Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIPFA: Generating IPA Pronunciation from Audio
Paper and Code


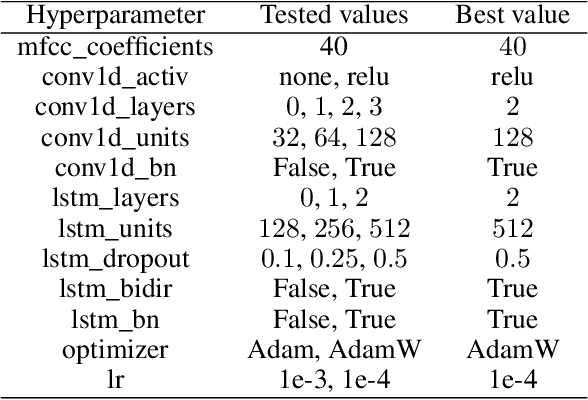
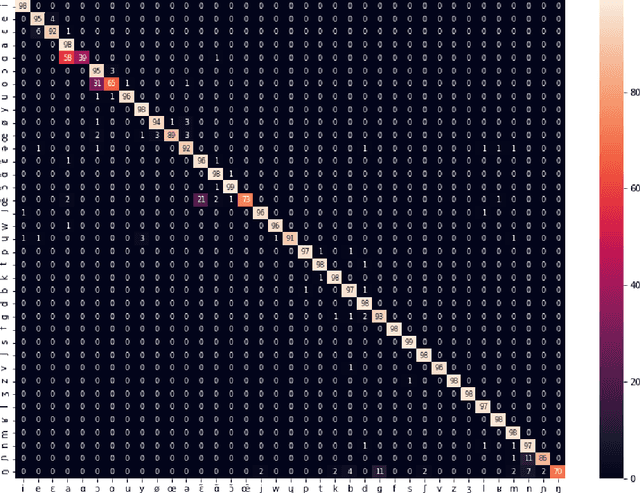
Transcribing spoken audio samples into International Phonetic Alphabet (IPA) has long been reserved for experts. In this study, we instead examined the use of an Artificial Neural Network (ANN) model to automatically extract the IPA pronunciation of a word based on its audio pronunciation, hence its name Generating IPA Pronunciation From Audio (GIPFA). Based on the French Wikimedia dictionary, we trained our model which then correctly predicted 75% of the IPA pronunciations tested. Interestingly, by studying inference errors, the model made it possible to highlight possible errors in the dataset as well as identifying the closest phonemes in French.
* 8 pages, 2 figures, 7 tables
View paper on