 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Entropy in Deep Learning of Classifiers Is Unnecessary -- ISBE Error is All You Need
Nov 27, 2023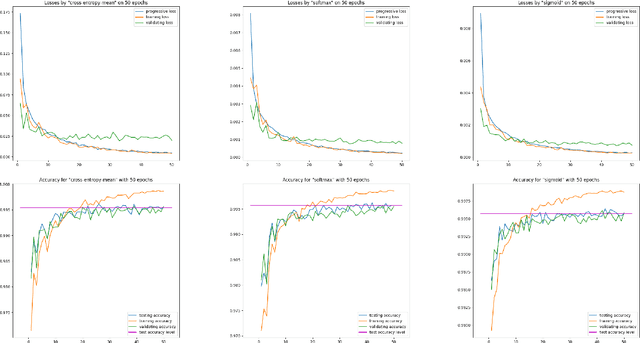
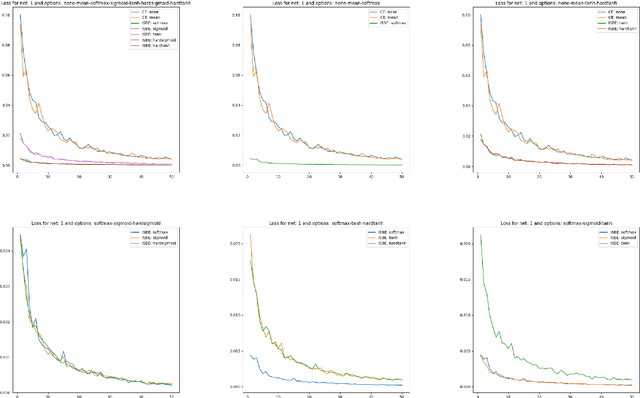


In deep learning classifiers, the cost function usually takes the form of a combination of SoftMax and CrossEntropy functions. The SoftMax unit transforms the scores predicted by the model network into assessments of the degree (probabilities) of an object's membership to a given class. On the other hand, CrossEntropy measures the divergence of this prediction from the distribution of target scores. This work introduces the ISBE functionality, justifying the thesis about the redundancy of cross entropy computation in deep learning of classifiers. Not only can we omit the calculation of entropy, but also, during back-propagation, there is no need to direct the error to the normalization unit for its backward transformation. Instead, the error is sent directly to the model's network. Using examples of perceptron and convolutional networks as classifiers of images from the MNIST collection, it is observed for ISBE that results are not degraded with SoftMax only, but also with other activation functions such as Sigmoid, Tanh, or their hard variants HardSigmoid and HardTanh. Moreover, up to three percent of time is saved within the total time of forward and backward stages. The article is addressed mainly to programmers and students interested in deep model learning. For example, it illustrates in code snippets possible ways to implement ISBE units, but also formally proves that the softmax trick only applies to the class of softmax functions with relocations.
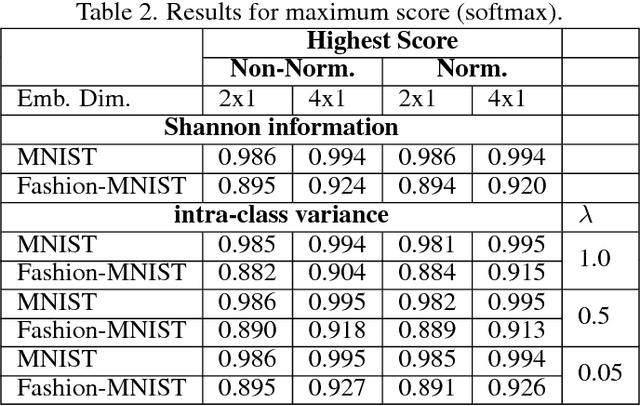
On Intra-Class Variance for Deep Learning of Classifiers
Jan 31, 2019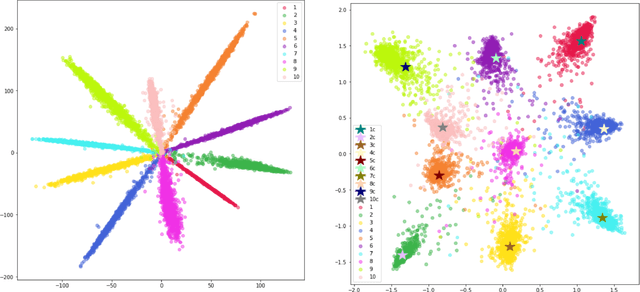

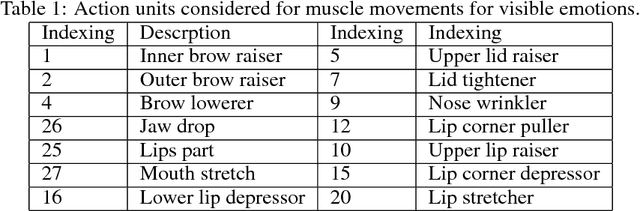
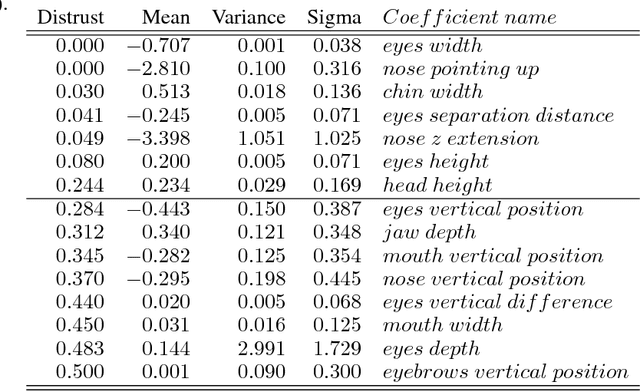
Several computer algorithms for recognition of visible human emotions are compared at the web camera scenario using CNN/MMOD face detector. The recognition refers to four face expressions: smile, surprise, anger, and neutral. At the feature extraction stage, the following three concepts of face description are confronted: (a) static 2D face geometry represented by its 68 characteristic landmarks (FP68); (b) dynamic 3D geometry defined by motion parameters for eight distinguished face parts (denoted as AU8) of personalized Candide-3 model; (c) static 2D visual description as 2D array of gray scale pixels (known as facial raw image). At the classification stage, the performance of two major models are analyzed: (a) support vector machine (SVM) with kernel options; (b) convolutional neural network (CNN) with variety of relevant tensor processing layers and blocks of them. The models are trained for frontal views of human faces while they are tested for arbitrary head poses. For geometric features, the success rate (accuracy) indicate nearly triple increase of performance of CNN with respect to SVM classifiers. For raw images, CNN outperforms in accuracy its best geometric counterpart (AU/CNN) by about 30 percent while the best SVM solutions are inferior nearly four times. For F-score the high advantage of raw/CNN over geometric/CNN and geometric/SVM is observed, as well. We conclude that contrary to CNN based emotion classifiers, the generalization capability wrt human head pose is for SVM based emotion classifiers poor.
Human Face Expressions from Images - 2D Face Geometry and 3D Face Local Motion versus Deep Neural Features
Jan 31, 2019

Several computer algorithms for recognition of visible human emotions are compared at the web camera scenario using CNN/MMOD face detector. The recognition refers to four face expressions: smile, surprise, anger, and neutral. At the feature extraction stage, the following three concepts of face description are confronted: (a) static 2D face geometry represented by its 68 characteristic landmarks (FP68); (b) dynamic 3D geometry defined by motion parameters for eight distinguished face parts (denoted as AU8) of personalized Candide-3 model; (c) static 2D visual description as 2D array of gray scale pixels (known as facial raw image). At the classification stage, the performance of two major models are analyzed: (a) support vector machine (SVM) with kernel options; (b) convolutional neural network (CNN) with variety of relevant tensor processing layers and blocks of them. The models are trained for frontal views of human faces while they are tested for arbitrary head poses. For geometric features, the success rate (accuracy) indicate nearly triple increase of performance of CNN with respect to SVM classifiers. For raw images, CNN outperforms in accuracy its best geometric counterpart (AU/CNN) by about 30 percent while the best SVM solutions are inferior nearly four times. For F-score the high advantage of raw/CNN over geometric/CNN and geometric/SVM is observed, as well. We conclude that contrary to CNN based emotion classifiers, the generalization capability wrt human head pose is for SVM based emotion classifiers poor.
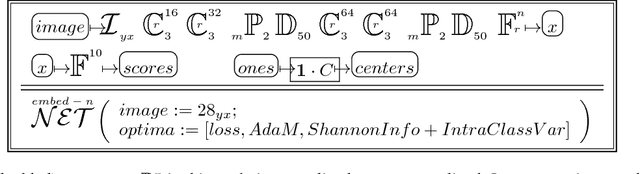
Symbolic Tensor Neural Networks for Digital Media - from Tensor Processing via BNF Graph Rules to CREAMS Applications
Sep 18, 2018This tutorial material on Convolutional Neural Networks (CNN) and its applications in digital media research is based on the concept of Symbolic Tensor Neural Networks. The set of STNN expressions is specified in Backus-Naur Form (BNF) which is annotated by constraints typical for labeled acyclic directed graphs (DAG). The BNF induction begins from a collection of neural unit symbols with extra (up to five) decoration fields (including tensor depth and sharing fields). The inductive rules provide not only the general graph structure but also the specific shortcuts for residual blocks of units. A syntactic mechanism for network fragments modularization is introduced via user defined units and their instances. Moreover, the dual BNF rules are specified in order to generate the Dual Symbolic Tensor Neural Network (DSTNN). The joined interpretation of STNN and DSTNN provides the correct flow of gradient tensors, back propagated at the training stage. The proposed symbolic representation of CNNs is illustrated for six generic digital media applications (CREAMS): Compression, Recognition, Embedding, Annotation, 3D Modeling for human-computer interfacing, and data Security based on digital media objects. In order to make the CNN description and its gradient flow complete, for all presented applications, the symbolic representations of mathematically defined loss/gain functions and gradient flow equations for all used core units, are given. The tutorial is to convince the reader that STNN is not only a convenient symbolic notation for public presentations of CNN based solutions for CREAMS problems but also that it is a design blueprint with a potential for automatic generation of application source code.