 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Bandits with Feedback for Cognitive Radar Networks
Jul 20, 2022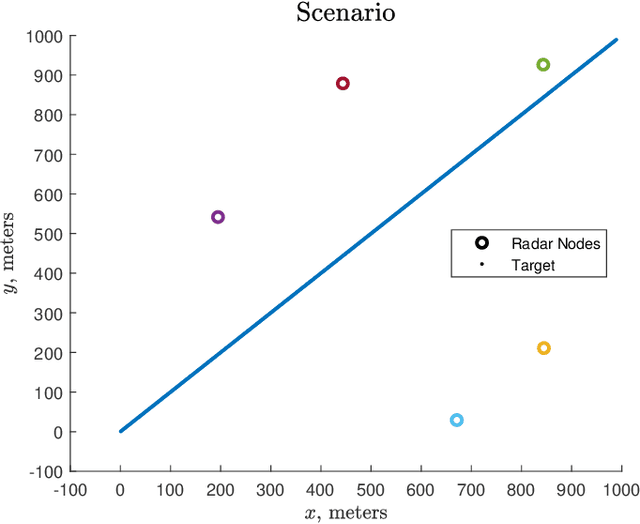
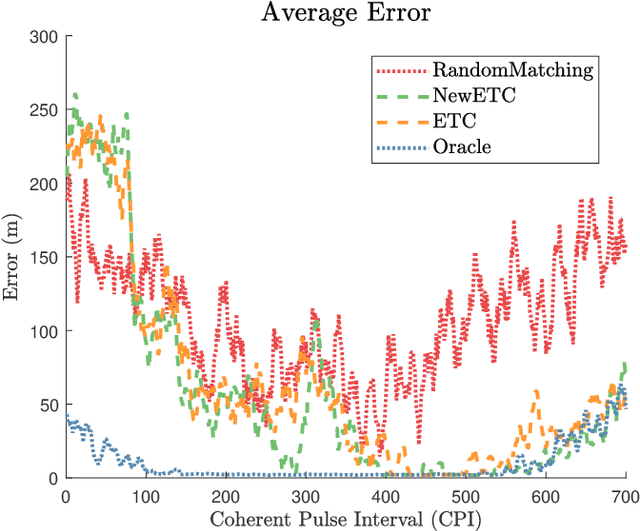
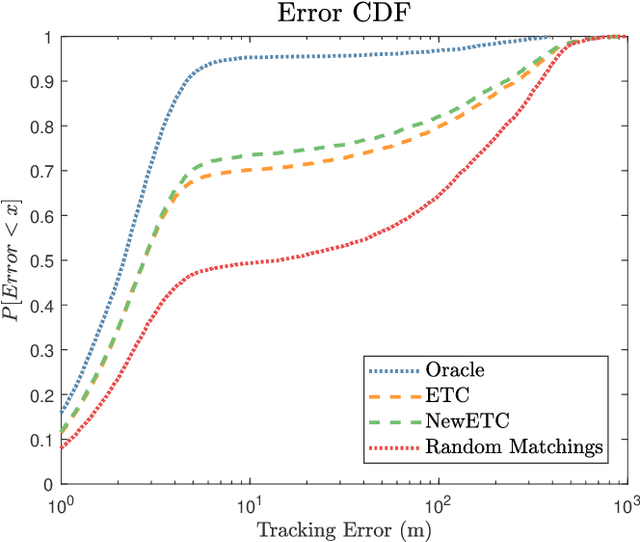
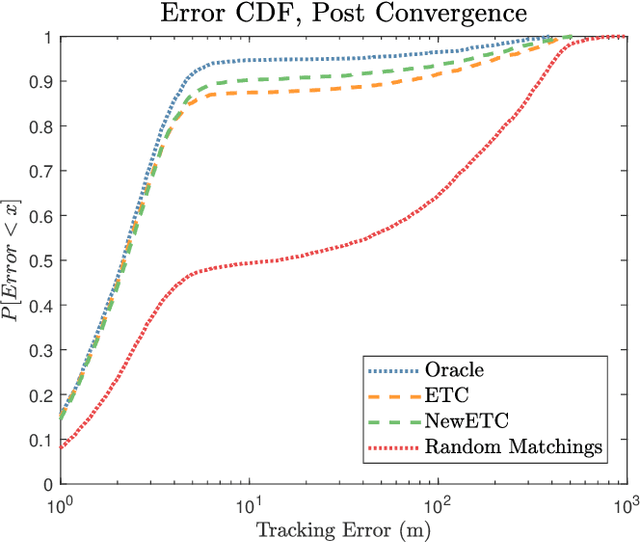
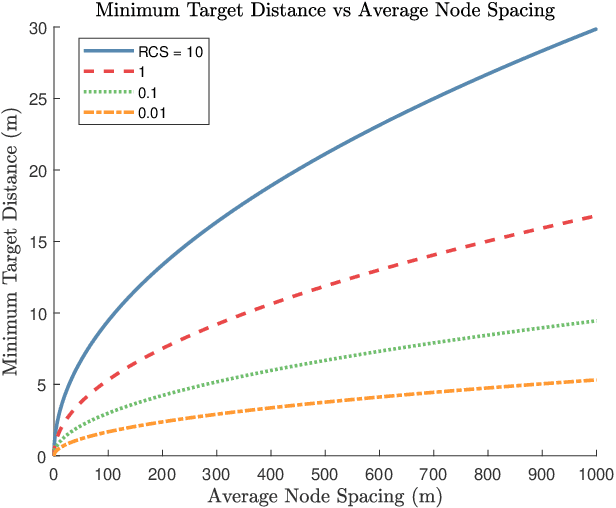
Completely decentralized Multi-Player Bandit models have demonstrated high localization accuracy at the cost of long convergence times in cognitive radar networks. Rather than model each radar node as an independent learner, entirely unable to swap information with other nodes in a network, in this work we construct a "central coordinator" to facilitate the exchange of information between radar nodes. We show that in interference-limited spectrum, where the signal to interference plus noise (SINR) ratio for the available bands may vary by location, a cognitive radar network (CRN) is able to use information from a central coordinator to reduce the number of time steps required to attain a given localization error. Importantly, each node is still able to learn separately. We provide a description of a network which has hybrid cognition in both a central coordinator and in each of the cognitive radar nodes, and examine the online machine learning algorithms which can be implemented in this structure.
Distributed Online Learning for Coexistence in Cognitive Radar Networks
Mar 11, 2022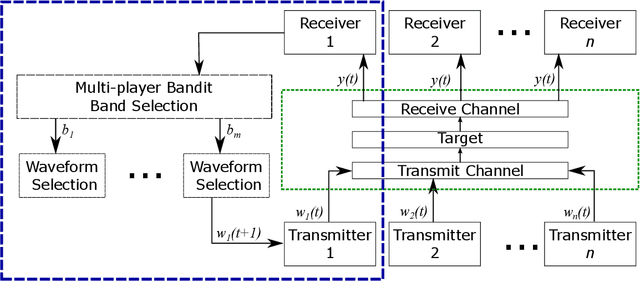

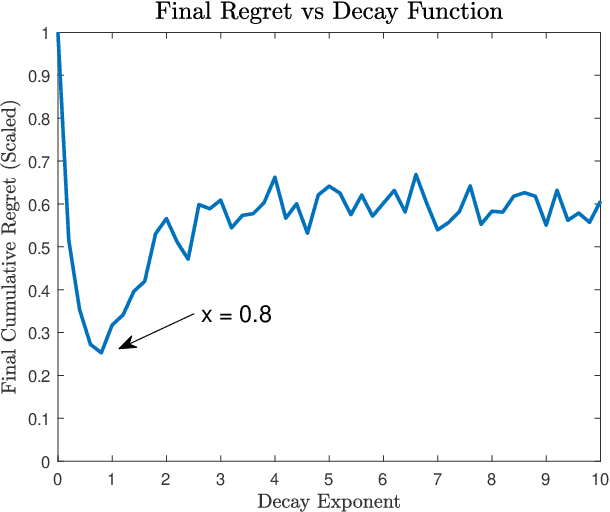
This work addresses the coexistence problem for radar networks. Specifically, we model a network of cooperative, independent, and non-communicating radar nodes which must share resources within the network as well as with non-cooperative nearby emitters. We approach this problem using online Machine Learning (ML) techniques. Online learning approaches are specifically preferred due to the fact that each radar node has no prior knowledge of the environment nor of the positions of the other radar nodes, and due to the sequential nature of the problem. For this task we specifically select the multi-player multi-armed bandit (MMAB) model, which poses the problem as a sequential game, where each radar node in a network makes independent selections of center frequency and waveform with the same goal of improving tracking performance for the network as a whole. For accurate tracking, each radar node communicates observations to a fusion center on set intervals. The fusion center has knowledge of the radar node placement, but cannot communicate to the individual nodes fast enough for waveform control. Every radar node in the network must learn the behavior of the environment, which includes rewards, interferer behavior, and target behavior. Our contributions include a mathematical description of the MMAB framework adapted to the radar network scenario. We conclude with a simulation study of several different network configurations. Experimental results show that iterative, online learning using MMAB outperforms the more traditional sense-and-avoid (SAA) and fixed-allocation approaches.