 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing a Family of Synthetic Datasets for Research on Bias in Machine Learning
Aug 03, 2021
A significant impediment to progress in research on bias in machine learning (ML) is the availability of relevant datasets. This situation is unlikely to change much given the sensitivity of such data. For this reason, there is a role for synthetic data in this research. In this short paper, we present one such family of synthetic data sets. We provide an overview of the data, describe how the level of bias can be varied, and present a simple example of an experiment on the data.
Using Pareto Simulated Annealing to Address Algorithmic Bias in Machine Learning
May 31, 2021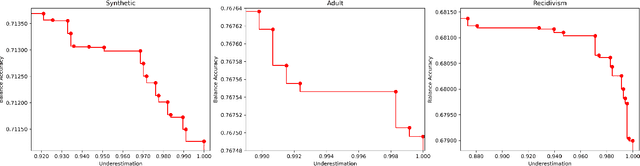

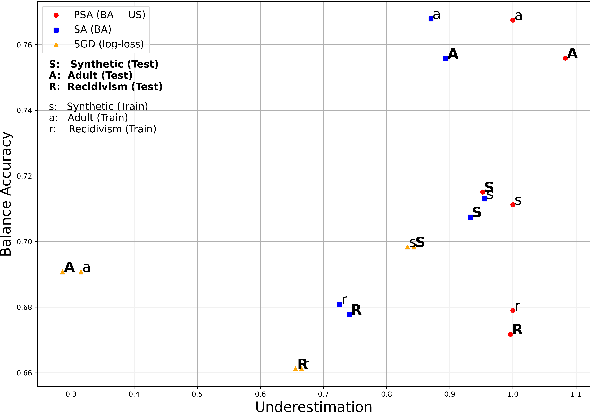
Algorithmic Bias can be due to bias in the training data or issues with the algorithm itself. These algorithmic issues typically relate to problems with model capacity and regularisation. This underestimation bias may arise because the model has been optimised for good generalisation accuracy without any explicit consideration of bias or fairness. In a sense, we should not be surprised that a model might be biased when it hasn't been "asked" not to be. In this paper, we consider including bias (underestimation) as an additional criterion in model training. We present a multi-objective optimisation strategy using Pareto Simulated Annealing that optimise for both balanced accuracy and underestimation. We demonstrate the effectiveness of this strategy on one synthetic and two real-world datasets.
Algorithmic Factors Influencing Bias in Machine Learning
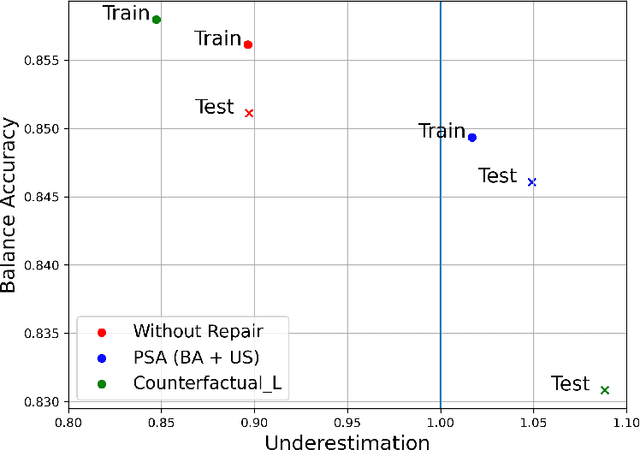
Apr 28, 2021
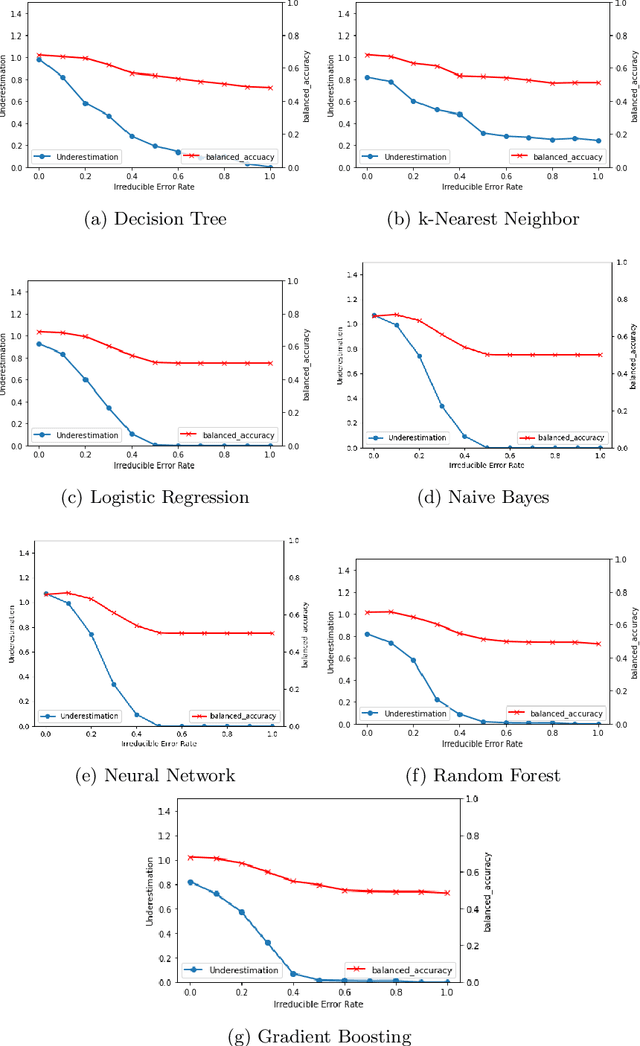
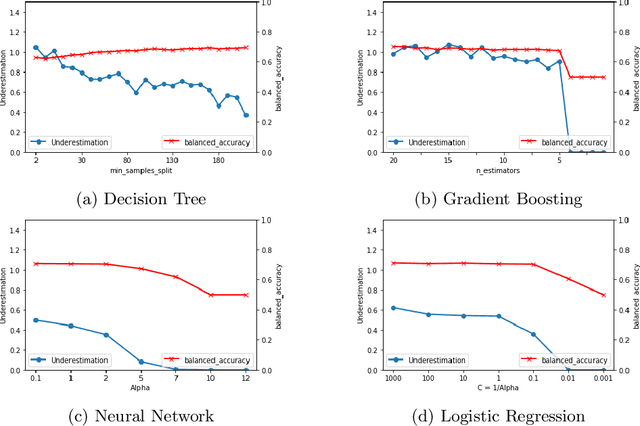
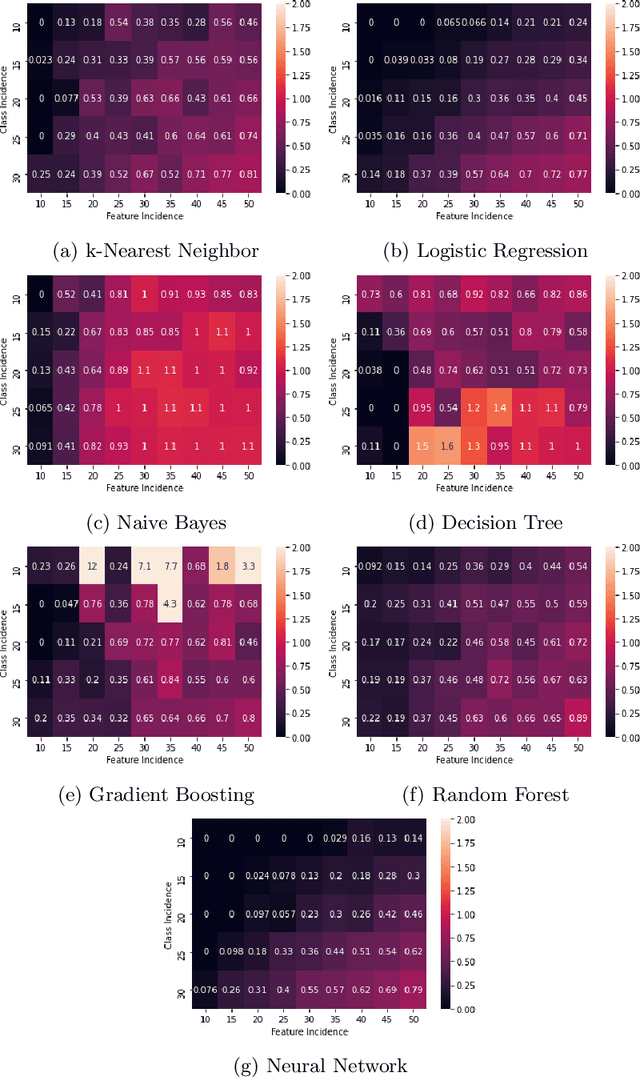
It is fair to say that many of the prominent examples of bias in Machine Learning (ML) arise from bias that is there in the training data. In fact, some would argue that supervised ML algorithms cannot be biased, they reflect the data on which they are trained. In this paper we demonstrate how ML algorithms can misrepresent the training data through underestimation. We show how irreducible error, regularization and feature and class imbalance can contribute to this underestimation. The paper concludes with a demonstration of how the careful management of synthetic counterfactuals can ameliorate the impact of this underestimation bias.