Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Factors Influencing Bias in Machine Learning
Paper and Code
Apr 28, 2021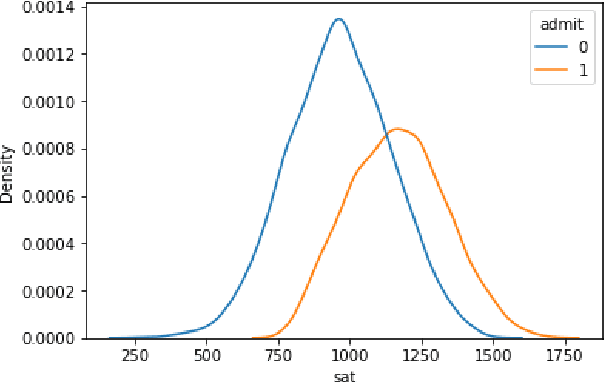
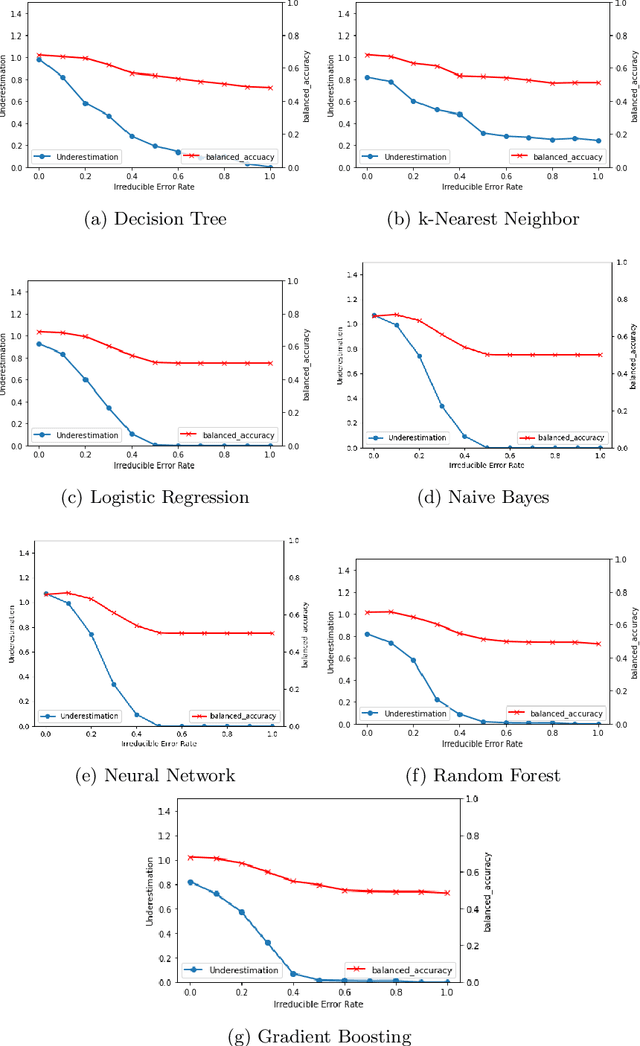
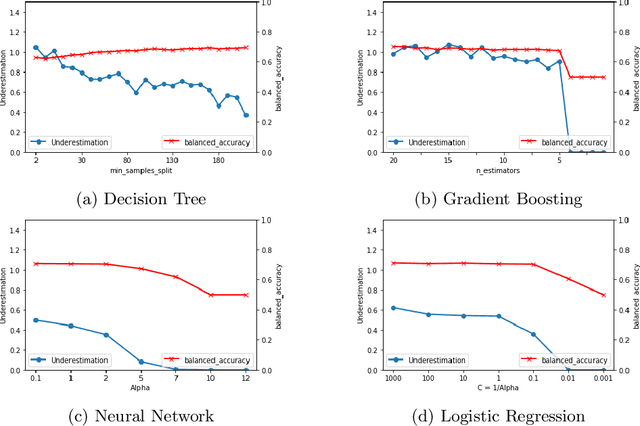
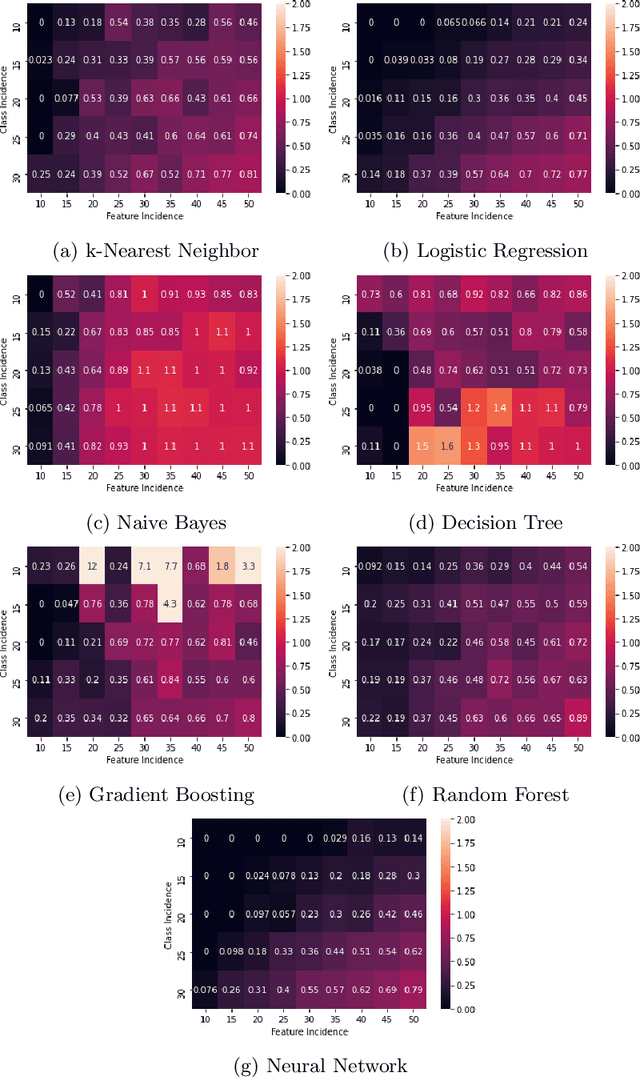
It is fair to say that many of the prominent examples of bias in Machine Learning (ML) arise from bias that is there in the training data. In fact, some would argue that supervised ML algorithms cannot be biased, they reflect the data on which they are trained. In this paper we demonstrate how ML algorithms can misrepresent the training data through underestimation. We show how irreducible error, regularization and feature and class imbalance can contribute to this underestimation. The paper concludes with a demonstration of how the careful management of synthetic counterfactuals can ameliorate the impact of this underestimation bias.
View paper on