 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace Non-cooperative Object Active Tracking with Deep Reinforcement Learning
Dec 18, 2021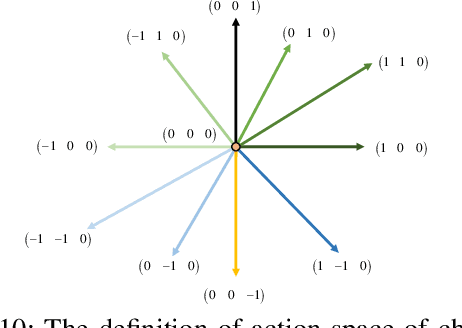

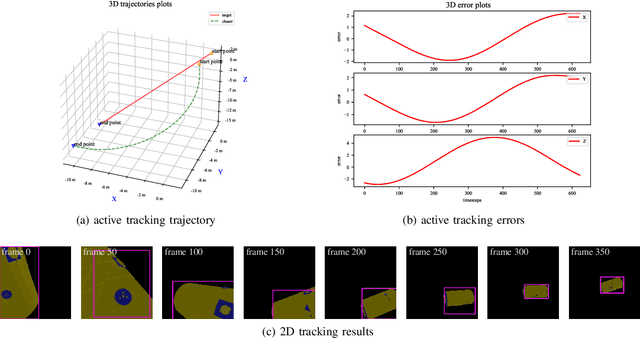
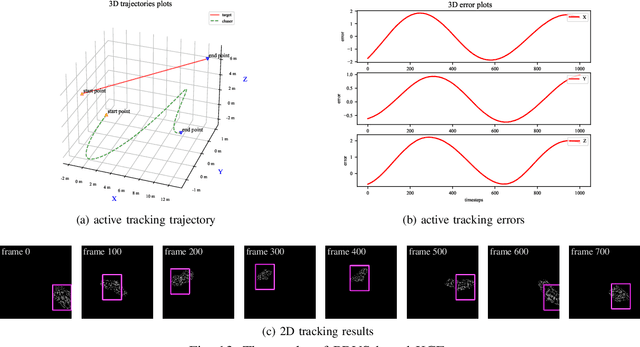
Active visual tracking of space non-cooperative object is significant for future intelligent spacecraft to realise space debris removal, asteroid exploration, autonomous rendezvous and docking. However, existing works often consider this task into different subproblems (e.g. image preprocessing, feature extraction and matching, position and pose estimation, control law design) and optimize each module alone, which are trivial and sub-optimal. To this end, we propose an end-to-end active visual tracking method based on DQN algorithm, named as DRLAVT. It can guide the chasing spacecraft approach to arbitrary space non-cooperative target merely relied on color or RGBD images, which significantly outperforms position-based visual servoing baseline algorithm that adopts state-of-the-art 2D monocular tracker, SiamRPN. Extensive experiments implemented with diverse network architectures, different perturbations and multiple targets demonstrate the advancement and robustness of DRLAVT. In addition, We further prove our method indeed learnt the motion patterns of target with deep reinforcement learning through hundreds of trial-and-errors.