 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedestrain detection for low-light vision proposal
Mar 17, 2023
The demand for pedestrian detection has created a challenging problem for various visual tasks such as image fusion. As infrared images can capture thermal radiation information, image fusion between infrared and visible images could significantly improve target detection under environmental limitations. In our project, we would approach by preprocessing our dataset with image fusion technique, then using Vision Transformer model to detect pedestrians from the fused images. During the evaluation procedure, a comparison would be made between YOLOv5 and the revised ViT model performance on our fused images
Structure-guided Image Outpainting
Dec 21, 2022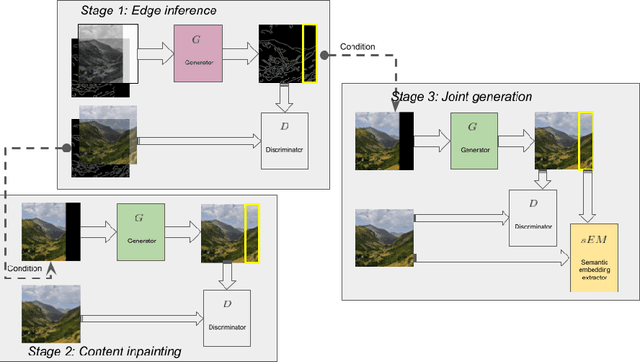
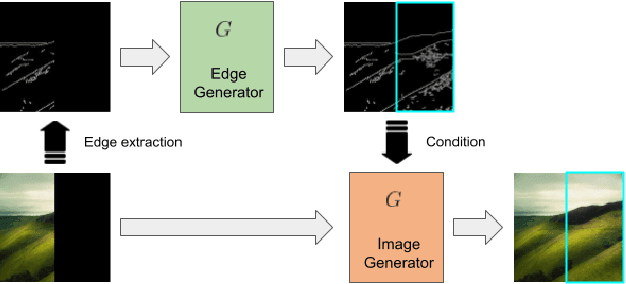


Deep learning techniques have made considerable progress in image inpainting, restoration, and reconstruction in the last few years. Image outpainting, also known as image extrapolation, lacks attention and practical approaches to be fulfilled, owing to difficulties caused by large-scale area loss and less legitimate neighboring information. These difficulties have made outpainted images handled by most of the existing models unrealistic to human eyes and spatially inconsistent. When upsampling through deconvolution to generate fake content, the naive generation methods may lead to results lacking high-frequency details and structural authenticity. Therefore, as our novelties to handle image outpainting problems, we introduce structural prior as a condition to optimize the generation quality and a new semantic embedding term to enhance perceptual sanity. we propose a deep learning method based on Generative Adversarial Network (GAN) and condition edges as structural prior in order to assist the generation. We use a multi-phase adversarial training scheme that comprises edge inference training, contents inpainting training, and joint training. The newly added semantic embedding loss is proved effective in practice.