 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Personality-Aware Interactions in Salesperson Dialogue Agents
Apr 25, 2025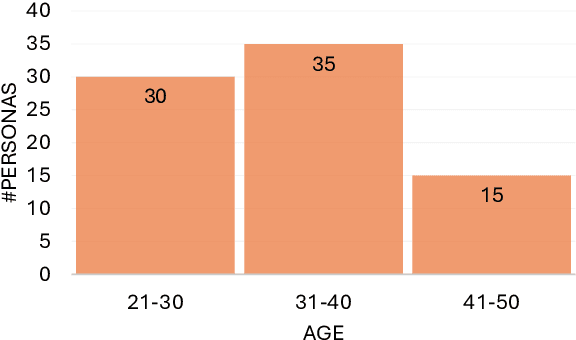
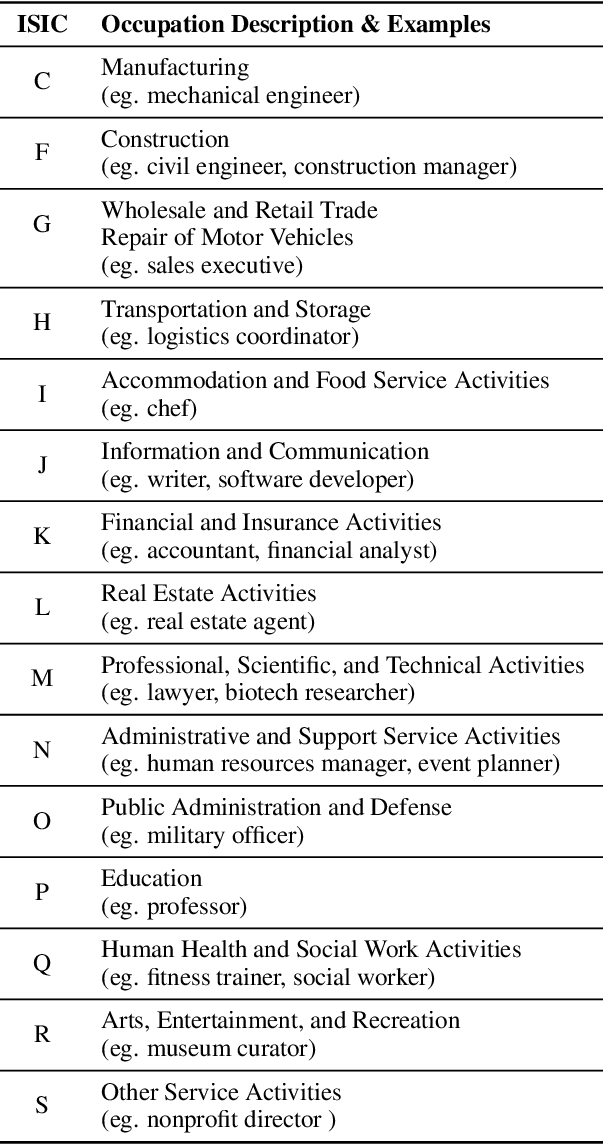
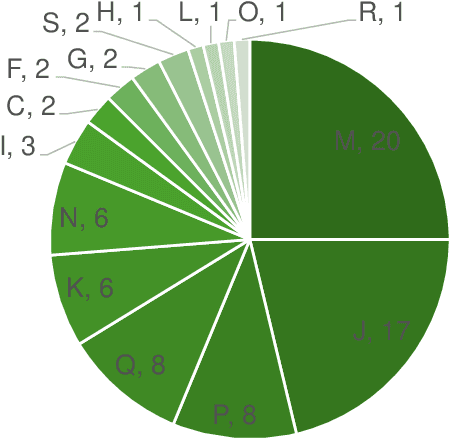
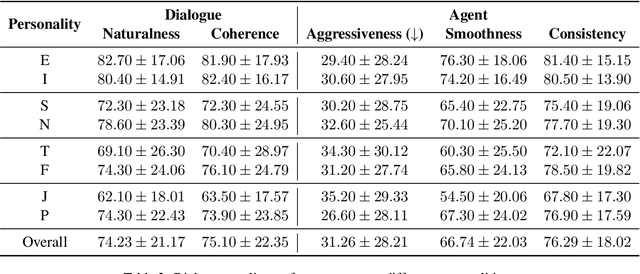
The integration of dialogue agents into the sales domain requires a deep understanding of how these systems interact with users possessing diverse personas. This study explores the influence of user personas, defined using the Myers-Briggs Type Indicator (MBTI), on the interaction quality and performance of sales-oriented dialogue agents. Through large-scale testing and analysis, we assess the pre-trained agent's effectiveness, adaptability, and personalization capabilities across a wide range of MBTI-defined user types. Our findings reveal significant patterns in interaction dynamics, task completion rates, and dialogue naturalness, underscoring the future potential for dialogue agents to refine their strategies to better align with varying personality traits. This work not only provides actionable insights for building more adaptive and user-centric conversational systems in the sales domain but also contributes broadly to the field by releasing persona-defined user simulators. These simulators, unconstrained by domain, offer valuable tools for future research and demonstrate the potential for scaling personalized dialogue systems across diverse applications.
Injecting Salesperson's Dialogue Strategies in Large Language Models with Chain-of-Thought Reasoning
Apr 29, 2024Recent research in dialogue systems and corpora has focused on two main categories: task-oriented (TOD) and open-domain (chit-chat) dialogues. TOD systems help users accomplish specific tasks, while open-domain systems aim to create engaging conversations. However, in real-world scenarios, user intents are often revealed during interactions. A recent study introduced SalesBot, which simulates dialogues transitioning from chit-chat to task-oriented scenarios to train sales agents. Unfortunately, the initial data lacked smooth transitions and coherent long-turn dialogues, resulting in poor naturalness in sales-customer interactions. To address these issues, this paper presents SalesBot 2.0, an improved dataset. It leverages commonsense knowledge from large language models (LLMs) through strategic prompting. Additionally, we introduce a novel model called SalesAgent, trained on salesperson's interactions, using chain-of-thought (CoT) reasoning. This model excels in transitioning topics, understanding user intents, and selecting appropriate strategies. Experiments using diverse user simulations validate the effectiveness of our method in controlling dialogue strategies in LLMs. Furthermore, SalesBot 2.0 enhances coherence and reduces aggression, facilitating better model learning for sales-customer interactions.
SalesBot 2.0: A Human-Like Intent-Guided Chit-Chat Dataset
Aug 28, 2023



In recent research on dialogue systems and corpora, there has been a significant focus on two distinct categories: task-oriented (TOD) and open-domain (chit-chat) dialogues. TOD systems aim to satisfy specific user goals, such as finding a movie to watch, whereas open-domain systems primarily focus on generating engaging conversations. A recent study by Chiu et al. (2022) introduced SalesBot, which provides simulators and a dataset with one-turn transition from chit-chat to task-oriented dialogues. However, the previously generated data solely relied on BlenderBot, which raised concerns about its long-turn naturalness and consistency during a conversation. To address this issue, this paper aims to build SalesBot 2.0, a revised version of the published data, by leveraging the commonsense knowledge of large language models (LLMs) through proper prompting. The objective is to gradually bridge the gap between chit-chat and TOD towards better naturalness and consistency. The newly released large-scale dataset with detailed annotations exhibits smoother transitions between topics and is more human-like in terms of naturalness and consistency. It can serve as a valuable resource for both academic research and commercial applications. Furthermore, our proposed framework can be applied to generate numerous dialogues with various target intents.
Vanishing Nodes: Another Phenomenon That Makes Training Deep Neural Networks Difficult
Oct 22, 2019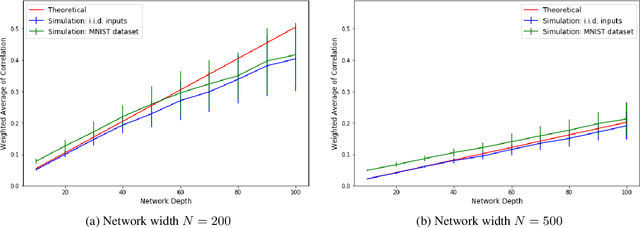

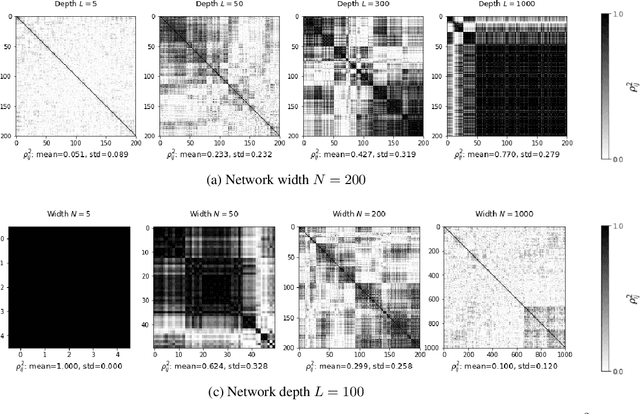
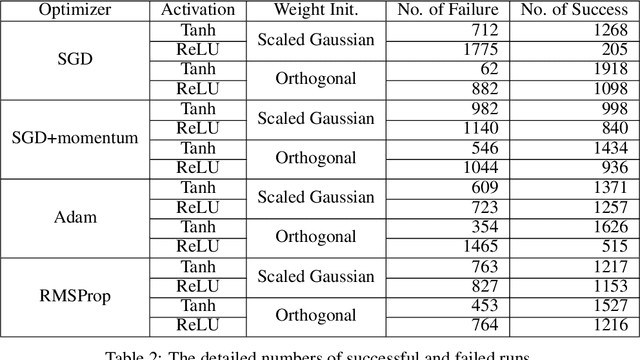
It is well known that the problem of vanishing/exploding gradients is a challenge when training deep networks. In this paper, we describe another phenomenon, called vanishing nodes, that also increases the difficulty of training deep neural networks. As the depth of a neural network increases, the network's hidden nodes have more highly correlated behavior. This results in great similarities between these nodes. The redundancy of hidden nodes thus increases as the network becomes deeper. We call this problem vanishing nodes, and we propose the metric vanishing node indicator (VNI) for quantitatively measuring the degree of vanishing nodes. The VNI can be characterized by the network parameters, which is shown analytically to be proportional to the depth of the network and inversely proportional to the network width. The theoretical results show that the effective number of nodes vanishes to one when the VNI increases to one (its maximal value), and that vanishing/exploding gradients and vanishing nodes are two different challenges that increase the difficulty of training deep neural networks. The numerical results from the experiments suggest that the degree of vanishing nodes will become more evident during back-propagation training, and that when the VNI is equal to 1, the network cannot learn simple tasks (e.g. the XOR problem) even when the gradients are neither vanishing nor exploding. We refer to this kind of gradients as the walking dead gradients, which cannot help the network converge when having a relatively large enough scale. Finally, the experiments show that the likelihood of failed training increases as the depth of the network increases. The training will become much more difficult due to the lack of network representation capability.