 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection, Retrieval, and Explanation Unified: A Violence Detection System Based on Knowledge Graphs and GAT
Jan 07, 2025


Recently, violence detection systems developed using unified multimodal models have achieved significant success and attracted widespread attention. However, most of these systems face two critical challenges: the lack of interpretability as black-box models and limited functionality, offering only classification or retrieval capabilities. To address these challenges, this paper proposes a novel interpretable violence detection system, termed the Three-in-One (TIO) System. The TIO system integrates knowledge graphs (KG) and graph attention networks (GAT) to provide three core functionalities: detection, retrieval, and explanation. Specifically, the system processes each video frame along with text descriptions generated by a large language model (LLM) for videos containing potential violent behavior. It employs ImageBind to generate high-dimensional embeddings for constructing a knowledge graph, uses GAT for reasoning, and applies lightweight time series modules to extract video embedding features. The final step connects a classifier and retriever for multi-functional outputs. The interpretability of KG enables the system to verify the reasoning process behind each output. Additionally, the paper introduces several lightweight methods to reduce the resource consumption of the TIO system and enhance its efficiency. Extensive experiments conducted on the XD-Violence and UCF-Crime datasets validate the effectiveness of the proposed system. A case study further reveals an intriguing phenomenon: as the number of bystanders increases, the occurrence of violent behavior tends to decrease.
Injecting Explainability and Lightweight Design into Weakly Supervised Video Anomaly Detection Systems
Dec 28, 2024Weakly Supervised Monitoring Anomaly Detection (WSMAD) utilizes weak supervision learning to identify anomalies, a critical task for smart city monitoring. However, existing multimodal approaches often fail to meet the real-time and interpretability requirements of edge devices due to their complexity. This paper presents TCVADS (Two-stage Cross-modal Video Anomaly Detection System), which leverages knowledge distillation and cross-modal contrastive learning to enable efficient, accurate, and interpretable anomaly detection on edge devices.TCVADS operates in two stages: coarse-grained rapid classification and fine-grained detailed analysis. In the first stage, TCVADS extracts features from video frames and inputs them into a time series analysis module, which acts as the teacher model. Insights are then transferred via knowledge distillation to a simplified convolutional network (student model) for binary classification. Upon detecting an anomaly, the second stage is triggered, employing a fine-grained multi-class classification model. This stage uses CLIP for cross-modal contrastive learning with text and images, enhancing interpretability and achieving refined classification through specially designed triplet textual relationships. Experimental results demonstrate that TCVADS significantly outperforms existing methods in model performance, detection efficiency, and interpretability, offering valuable contributions to smart city monitoring applications.
Explaining the Unexplained: Revealing Hidden Correlations for Better Interpretability
Dec 02, 2024

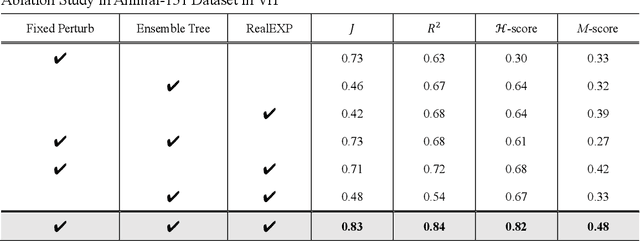

Deep learning has achieved remarkable success in processing and managing unstructured data. However, its "black box" nature imposes significant limitations, particularly in sensitive application domains. While existing interpretable machine learning methods address some of these issues, they often fail to adequately consider feature correlations and provide insufficient evaluation of model decision paths. To overcome these challenges, this paper introduces Real Explainer (RealExp), an interpretability computation method that decouples the Shapley Value into individual feature importance and feature correlation importance. By incorporating feature similarity computations, RealExp enhances interpretability by precisely quantifying both individual feature contributions and their interactions, leading to more reliable and nuanced explanations. Additionally, this paper proposes a novel interpretability evaluation criterion focused on elucidating the decision paths of deep learning models, going beyond traditional accuracy-based metrics. Experimental validations on two unstructured data tasks -- image classification and text sentiment analysis -- demonstrate that RealExp significantly outperforms existing methods in interpretability. Case studies further illustrate its practical value: in image classification, RealExp aids in selecting suitable pre-trained models for specific tasks from an interpretability perspective; in text classification, it enables the optimization of models and approximates the performance of a fine-tuned GPT-Ada model using traditional bag-of-words approaches.
From Explicit Rules to Implicit Reasoning in an Interpretable Violence Monitoring System
Oct 29, 2024



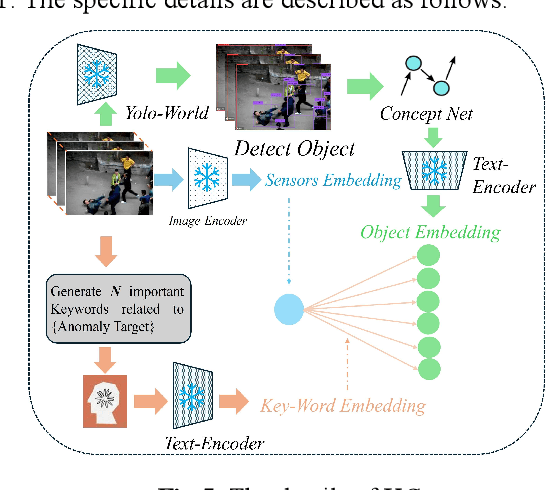
Recently, research based on pre-trained models has demonstrated outstanding performance in violence surveillance tasks. However, these black-box systems face challenges regarding explainability during training and inference processes. An important question is how to incorporate explicit knowledge into these implicit models, thereby designing expert-driven and interpretable violence surveillance systems. This paper proposes a new paradigm for weakly supervised violence monitoring (WSVM) called Rule base Violence monitoring (RuleVM). The proposed RuleVM uses a dual-branch structure for different designs for images and text. One of the branches is called the implicit branch, which uses only visual features for coarse-grained binary classification. In this branch, image feature extraction is divided into two channels: one responsible for extracting scene frames and the other focusing on extracting actions. The other branch is called the explicit branch, which utilizes language-image alignment to perform fine-grained classification. For the language channel design in the explicit branch, the proposed RuleCLIP uses the state-of-the-art YOLO-World model to detect objects and actions in video frames, and association rules are identified through data mining methods as descriptions of the video. Leveraging the dual?branch architecture, RuleVM achieves interpretable coarse?grained and fine-grained violence surveillance. Extensive experiments were conducted on two commonly used benchmarks, and the results show that RuleCLIP achieved the best performance in both coarse-grained and fine-grained detection, significantly outperforming existing state-of-the-art methods. Moreover, interpretability experiments uncovered some interesting rules, such as the observation that as the number of people increases, the risk level of violent behavior also rises.