 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Optimization of Clustering-based Scheduling for Multi-workflow On Clouds Considering Fairness
May 23, 2022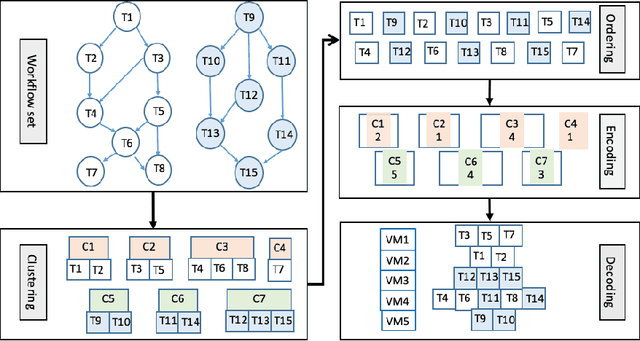

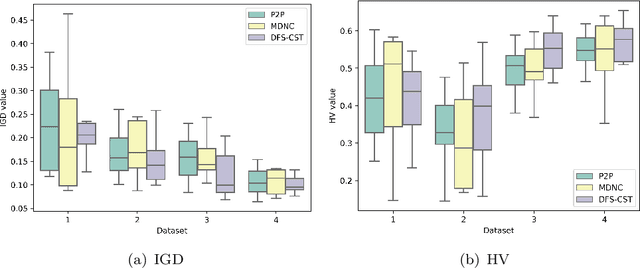
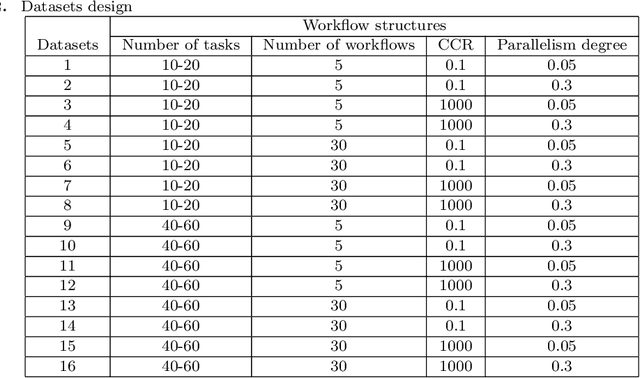
Distributed computing, such as cloud computing, provides promising platforms to execute multiple workflows. Workflow scheduling plays an important role in multi-workflow execution with multi-objective requirements. Although there exist many multi-objective scheduling algorithms, they focus mainly on optimizing makespan and cost for a single workflow. There is a limited research on multi-objective optimization for multi-workflow scheduling. Considering multi-workflow scheduling, there is an additional key objective to maintain the fairness of workflows using the resources. To address such issues, this paper first defines a new multi-objective optimization model based on makespan, cost, and fairness, and then proposes a global clustering-based multi-workflow scheduling strategy for resource allocation. Experimental results show that the proposed approach performs better than the compared algorithms without significant compromise of the overall makespan and cost as well as individual fairness, which can guide the simulation workflow scheduling on clouds.
Linear Context Transform Block
Sep 06, 2019



Squeeze-and-Excitation (SE) block presents a channel attention mechanism for modeling the global context via explicitly capturing dependencies between channels. However, we still poorly understand for SE block. In this work, we first revisit the SE block and present a detailed empirical study of the relationship between global context and attention distribution, based on which we further propose a simple yet effective module. We call this module Linear Context Transform (LCT) block, which implicitly captures dependencies between channels and linearly transforms the global context of each channel. LCT block is extremely lightweight with negligible parameters and computations. Extensive experiments show that LCT block outperforms SE block in image classification on ImageNet and object detection/segmentation on COCO across many models. Moreover, we also demonstrate that LCT block can yield consistent performance gains for existing state-of-the-art detection architectures. For examples, LCT block brings 1.5$\sim$1.7% AP$^{bbox}$ and 1.0%$\sim$1.2% AP$^{mask}$ gains independently of the detector strength on COCO benchmark. We hope our work will provide a new insight into the channel attention