 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrow with the Flow: 4D Reconstruction of Growing Plants with Gaussian Flow Fields
Feb 09, 2026Modeling the time-varying 3D appearance of plants during their growth poses unique challenges: unlike many dynamic scenes, plants generate new geometry over time as they expand, branch, and differentiate. Recent motion modeling techniques are ill-suited to this problem setting. For example, deformation fields cannot introduce new geometry, and 4D Gaussian splatting constrains motion to a linear trajectory in space and time and cannot track the same set of Gaussians over time. Here, we introduce a 3D Gaussian flow field representation that models plant growth as a time-varying derivative over Gaussian parameters -- position, scale, orientation, color, and opacity -- enabling nonlinear and continuous-time growth dynamics. To initialize a sufficient set of Gaussian primitives, we reconstruct the mature plant and learn a process of reverse growth, effectively simulating the plant's developmental history in reverse. Our approach achieves superior image quality and geometric accuracy compared to prior methods on multi-view timelapse datasets of plant growth, providing a new approach for appearance modeling of growing 3D structures.
Transientangelo: Few-Viewpoint Surface Reconstruction Using Single-Photon Lidar
Aug 23, 2024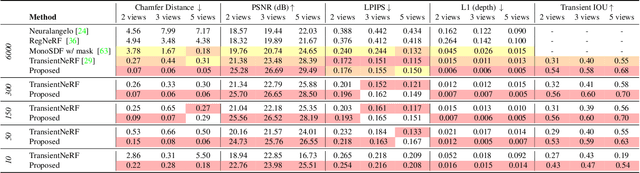
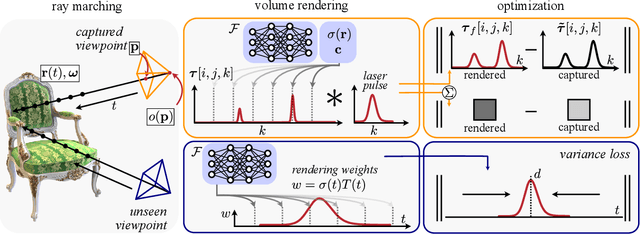
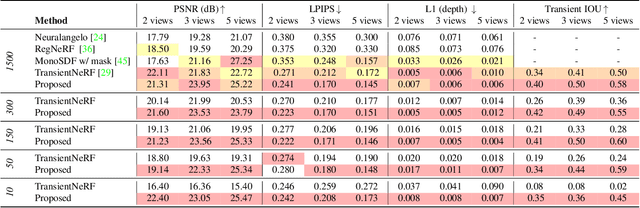
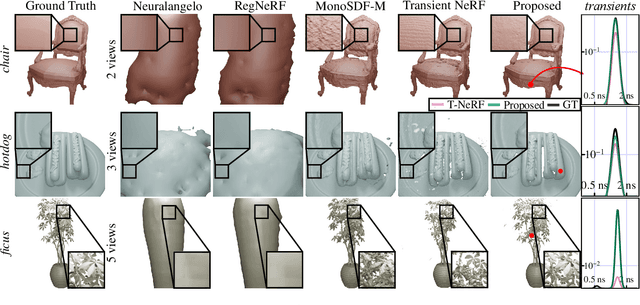
We consider the problem of few-viewpoint 3D surface reconstruction using raw measurements from a lidar system. Lidar captures 3D scene geometry by emitting pulses of light to a target and recording the speed-of-light time delay of the reflected light. However, conventional lidar systems do not output the raw, captured waveforms of backscattered light; instead, they pre-process these data into a 3D point cloud. Since this procedure typically does not accurately model the noise statistics of the system, exploit spatial priors, or incorporate information about downstream tasks, it ultimately discards useful information that is encoded in raw measurements of backscattered light. Here, we propose to leverage raw measurements captured with a single-photon lidar system from multiple viewpoints to optimize a neural surface representation of a scene. The measurements consist of time-resolved photon count histograms, or transients, which capture information about backscattered light at picosecond time scales. Additionally, we develop new regularization strategies that improve robustness to photon noise, enabling accurate surface reconstruction with as few as 10 photons per pixel. Our method outperforms other techniques for few-viewpoint 3D reconstruction based on depth maps, point clouds, or conventional lidar as demonstrated in simulation and with captured data.
CFDP: Common Frequency Domain Pruning
Jun 07, 2023As the saying goes, sometimes less is more -- and when it comes to neural networks, that couldn't be more true. Enter pruning, the art of selectively trimming away unnecessary parts of a network to create a more streamlined, efficient architecture. In this paper, we introduce a novel end-to-end pipeline for model pruning via the frequency domain. This work aims to shed light on the interoperability of intermediate model outputs and their significance beyond the spatial domain. Our method, dubbed Common Frequency Domain Pruning (CFDP) aims to extrapolate common frequency characteristics defined over the feature maps to rank the individual channels of a layer based on their level of importance in learning the representation. By harnessing the power of CFDP, we have achieved state-of-the-art results on CIFAR-10 with GoogLeNet reaching an accuracy of 95.25%, that is, +0.2% from the original model. We also outperform all benchmarks and match the original model's performance on ImageNet, using only 55% of the trainable parameters and 60% of the FLOPs. In addition to notable performances, models produced via CFDP exhibit robustness to a variety of configurations including pruning from untrained neural architectures, and resistance to adversarial attacks. The implementation code can be found at https://github.com/Skhaki18/CFDP.