 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermination of class-specific variables in nonparametric multiple-class classification
May 07, 2022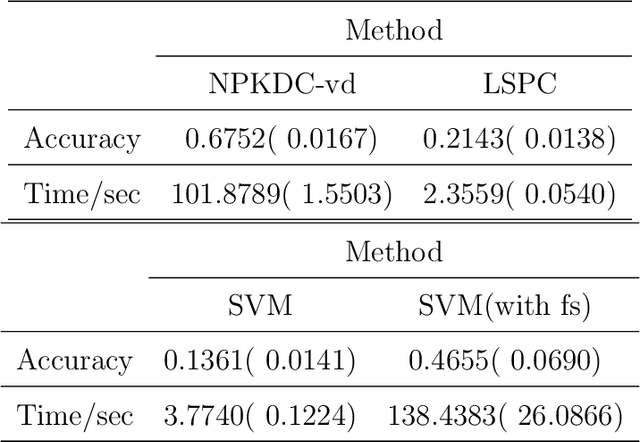
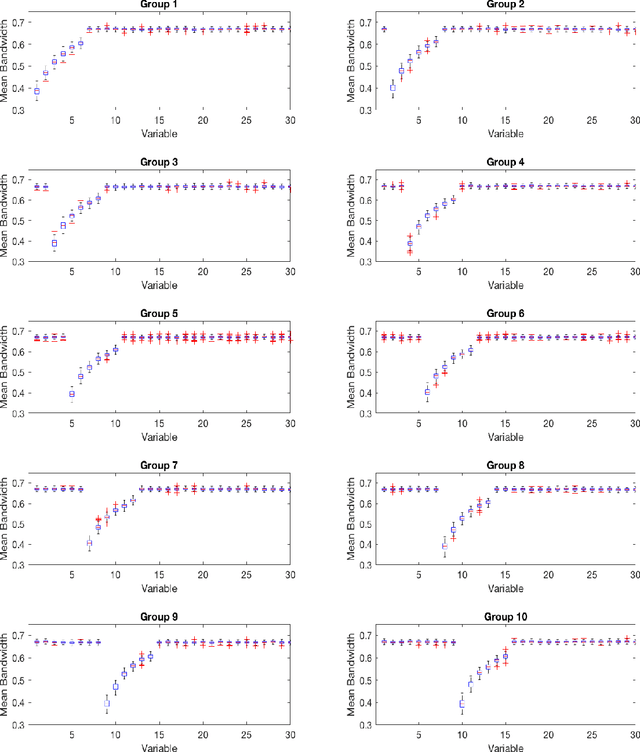
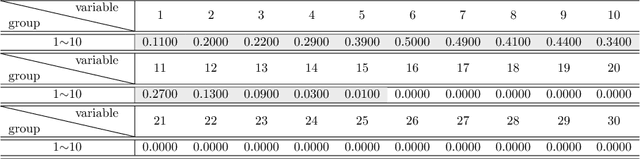
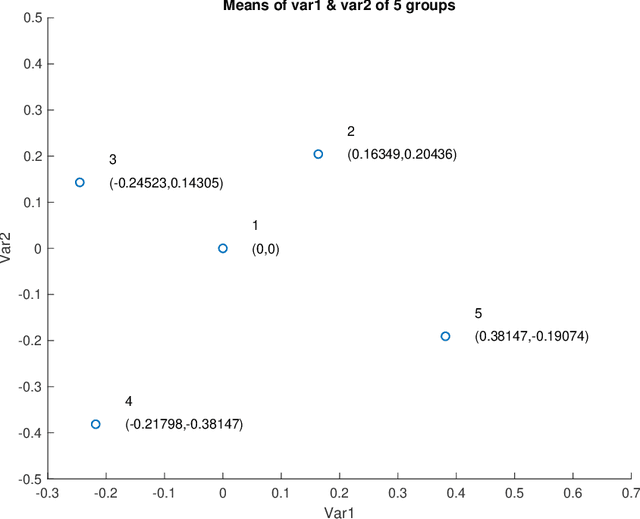
As technology advanced, collecting data via automatic collection devices become popular, thus we commonly face data sets with lengthy variables, especially when these data sets are collected without specific research goals beforehand. It has been pointed out in the literature that the difficulty of high-dimensional classification problems is intrinsically caused by too many noise variables useless for reducing classification error, which offer less benefits for decision-making, and increase complexity, and confusion in model-interpretation. A good variable selection strategy is therefore a must for using such kinds of data well; especially when we expect to use their results for the succeeding applications/studies, where the model-interpretation ability is essential. hus, the conventional classification measures, such as accuracy, sensitivity, precision, cannot be the only performance tasks. In this paper, we propose a probability-based nonparametric multiple-class classification method, and integrate it with the ability of identifying high impact variables for individual class such that we can have more information about its classification rule and the character of each class as well. The proposed method can have its prediction power approximately equal to that of the Bayes rule, and still retains the ability of "model-interpretation." We report the asymptotic properties of the proposed method, and use both synthesized and real data sets to illustrate its properties under different classification situations. We also separately discuss the variable identification, and training sample size determination, and summarize those procedures as algorithms such that users can easily implement them with different computing languages.
Fast Multi-Class Probabilistic Classifier by Sparse Non-parametric Density Estimation
Jan 04, 2019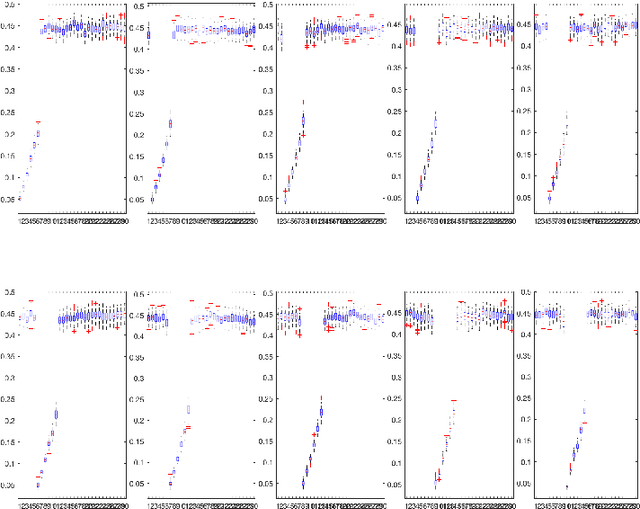
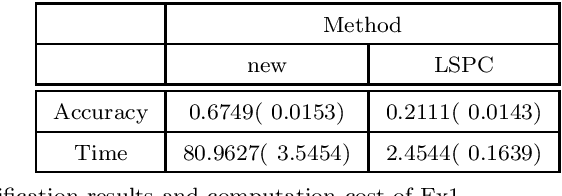
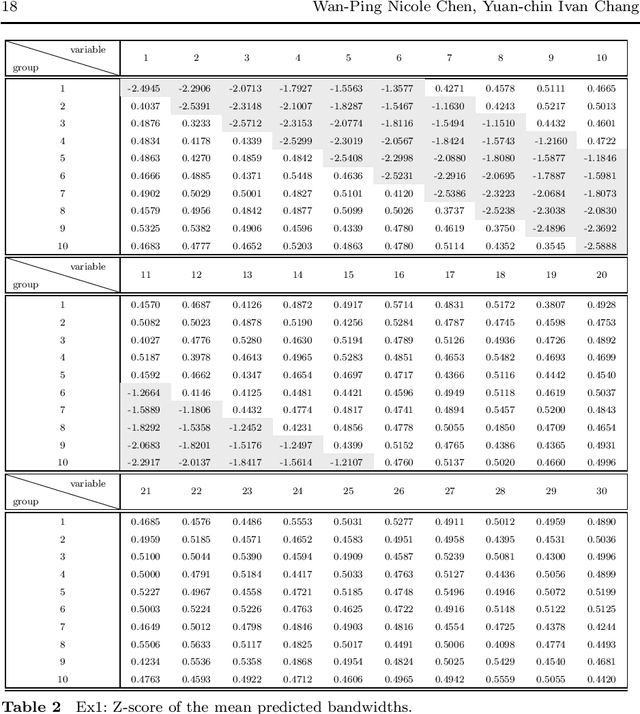
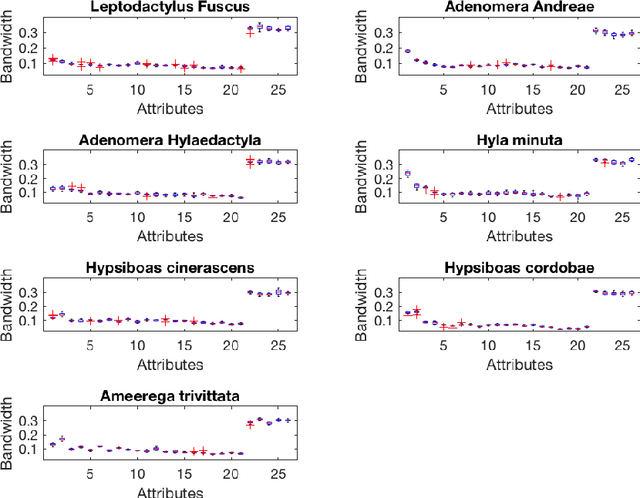
The model interpretation is essential in many application scenarios and to build a classification model with a ease of model interpretation may provide useful information for further studies and improvement. It is common to encounter with a lengthy set of variables in modern data analysis, especially when data are collected in some automatic ways. This kinds of datasets may not collected with a specific analysis target and usually contains redundant features, which have no contribution to a the current analysis task of interest. Variable selection is a common way to increase the ability of model interpretation and is popularly used with some parametric classification models. There is a lack of studies about variable selection in nonparametric classification models such as the density estimation-based methods and this is especially the case for multiple-class classification situations. In this study we study multiple-class classification problems using the thought of sparse non-parametric density estimation and propose a method for identifying high impacts variables for each class. We present the asymptotic properties and the computation procedure for the proposed method together with some suggested sample size. We also repost the numerical results using both synthesized and some real data sets.