 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Symmetric Regressor for MRI-Based Assessment of Striatal Dopamine Transporter Uptake in Parkinson's Disease
Apr 18, 2024



Dopamine transporter (DAT) imaging is commonly used for monitoring Parkinson's disease (PD), where striatal DAT uptake amount is computed to assess PD severity. However, DAT imaging has a high cost and the risk of radiance exposure and is not available in general clinics. Recently, MRI patch of the nigral region has been proposed as a safer and easier alternative. This paper proposes a symmetric regressor for predicting the DAT uptake amount from the nigral MRI patch. Acknowledging the symmetry between the right and left nigrae, the proposed regressor incorporates a paired input-output model that simultaneously predicts the DAT uptake amounts for both the right and left striata. Moreover, it employs a symmetric loss that imposes a constraint on the difference between right-to-left predictions, resembling the high correlation in DAT uptake amounts in the two lateral sides. Additionally, we propose a symmetric Monte-Carlo (MC) dropout method for providing a fruitful uncertainty estimate of the DAT uptake prediction, which utilizes the above symmetry. We evaluated the proposed approach on 734 nigral patches, which demonstrated significantly improved performance of the symmetric regressor compared with the standard regressors while giving better explainability and feature representation. The symmetric MC dropout also gave precise uncertainty ranges with a high probability of including the true DAT uptake amounts within the range.
Reinforcing Medical Image Classifier to Improve Generalization on Small Datasets
Oct 07, 2019



With the advents of deep learning, improved image classification with complex discriminative models has been made possible. However, such deep models with increased complexity require a huge set of labeled samples to generalize the training. Such classification models can easily overfit when applied for medical images because of limited training data, which is a common problem in the field of medical image analysis. This paper proposes and investigates a reinforced classifier for improving the generalization under a few available training data. Partially following the idea of reinforcement learning, the proposed classifier uses a generalization-feedback from a subset of the training data to update its parameter instead of only using the conventional cross-entropy loss about the training data. We evaluate the improvement of the proposed classifier by applying it on three different classification problems against the standard deep classifiers equipped with existing overfitting-prevention techniques. Besides an overall improvement in classification performance, the proposed classifier showed remarkable characteristics of generalized learning, which can have great potential in medical classification tasks.
Reinforcement Learning-based Automatic Diagnosis of Acute Appendicitis in Abdominal CT
Sep 02, 2019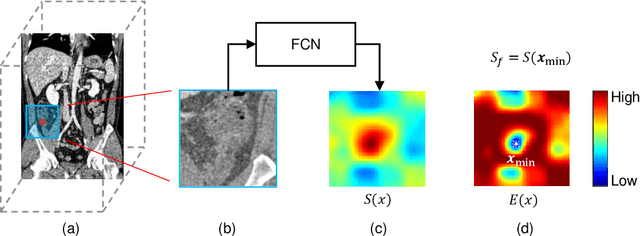

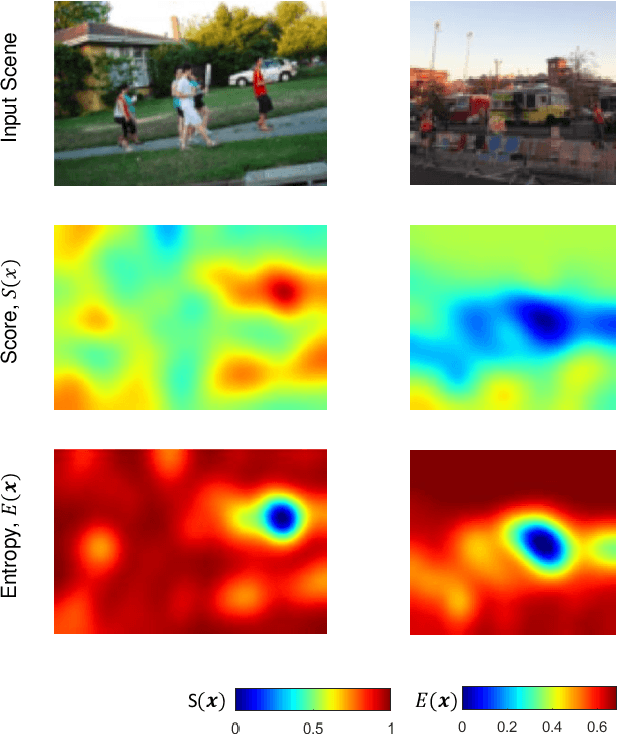
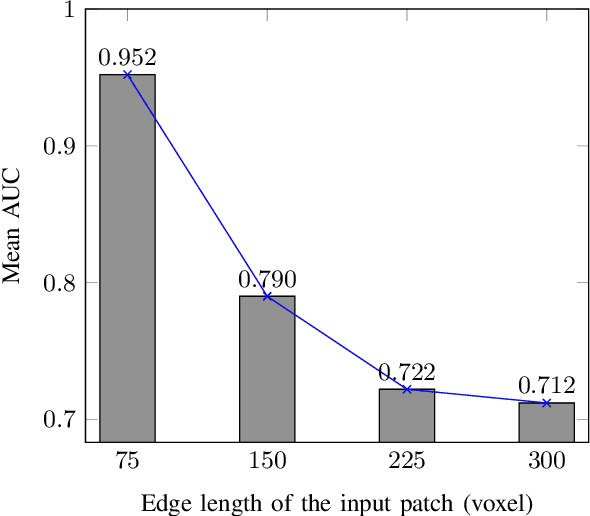
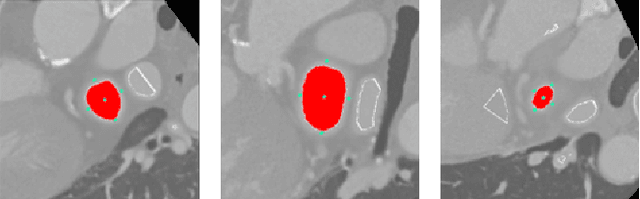
Acute appendicitis characterized by a painful inflammation of the vermiform appendix is one of the most common surgical emergencies. Localizing the appendix is challenging due to its unclear anatomy amidst the complex colon-structure as observed in the conventional CT views, resulting in a time-consuming diagnosis. End-to-end learning of a convolutional neural network (CNN) is also not likely to be useful because of the negligible size of the appendix compared with the abdominal CT volume. With no prior computational approaches to the best of our knowledge, we propose the first computerized automation for acute appendicitis diagnosis. In our approach, we utilize a reinforcement learning agent deployed in the lower abdominal region to obtain the appendix location first to reduce the search space for diagnosis. Then, we obtain the classification scores (i.e., the likelihood of acute appendicitis) for the local neighborhood around the localized position, using a CNN trained only on a small appendix patch per volume. From the spatial representation of the resultant scores, we finally define a region of low-entropy (RLE) to choose the optimal diagnosis score, which helps improve the classification accuracy showing robustness even under high appendix localization error cases. In our experiment with 319 abdominal CT volumes, the proposed RLE-based decision with prior localization showed significant improvement over the standard CNN-based diagnosis approaches.
Automatic Left Atrial Appendage Orifice Detection for Preprocedural Planning of Appendage Closure
Apr 02, 2019


In preoperative planning of left atrial appendage closure (LAAC) with CT angiography, the assessment of the appendage orifice plays a crucial role in choosing an appropriate LAAC device size and a proper C-arm angulation. However, accurate orifice detection is laborious because of the high anatomic variation of the appendage, as well as the unclear orifice position and orientation in the available views. We propose an automatic orifice detection approach performing a search on the principal medial axis of the appendage, where we present an efficient iterative algorithm to grow the axis from the appendage to the left atrium. We propose to use the axis-to-surface distance of the appendage for efficient and effective detection. To localize the necessary initial seed for growing the medial axis, we train an artificial localization agent using an actor-critic reinforcement learning approach, defining the localization as a sequential decision process. The entire detection process takes only about 8 seconds, and the variance of the detected orifice with respect to annotations from two experts is calculated to be significantly small and less than the inter-observer variance. The proposed orifice search on the medial axis of the appendage comparing only its distance from the surface provides a simple, yet robust solution for orifice detection. While being the first fully automatic approach and providing a detection error below the inter-observer difference, our method improved the detection efficiency by eighteen times compared to the existing solution, therefore, can be potentially useful for physicians.
Partial Policy-based Reinforcement Learning for Anatomical Landmark Localization in 3D Medical Images
Jul 09, 2018

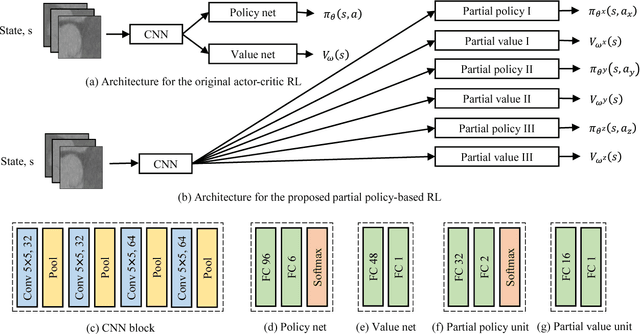
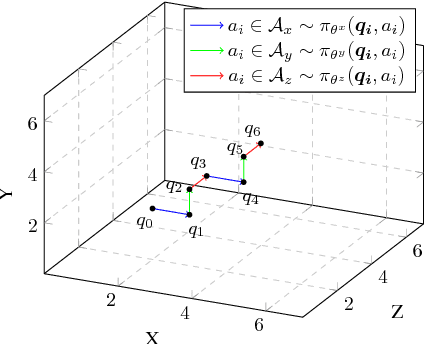
Deploying the idea of long-term cumulative return, reinforcement learning has shown remarkable performance in various fields. We propose a formulation of the landmark localization in 3D medical images as a reinforcement learning problem. Whereas value-based methods have been widely used to solve similar problems, we adopt an actor-critic based direct policy search method framed in a temporal difference learning approach. Successful behavior learning is challenging in large state and/or action spaces, requiring many trials. We introduce a partial policy-based reinforcement learning to enable solving the large problem of localization by learning the optimal policy on smaller partial domains. Independent actors efficiently learn the corresponding partial policies, each utilizing their own independent critic. The proposed policy reconstruction from the partial policies ensures a robust and efficient localization utilizing the sub-agents solving simple binary decision problems in their corresponding partial action spaces. The proposed reinforcement learning requires a small number of trials to learn the optimal behavior compared with the original behavior learning scheme.