 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Policy-based Reinforcement Learning for Anatomical Landmark Localization in 3D Medical Images
Paper and Code
Jul 09, 2018

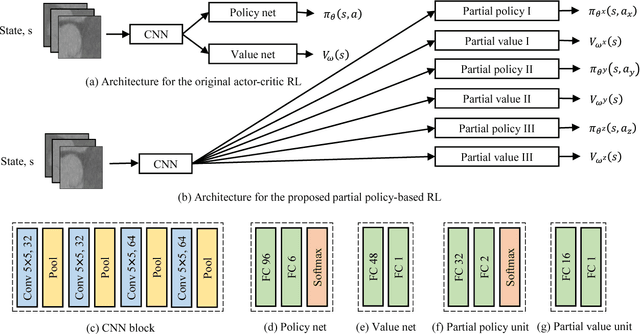
Deploying the idea of long-term cumulative return, reinforcement learning has shown remarkable performance in various fields. We propose a formulation of the landmark localization in 3D medical images as a reinforcement learning problem. Whereas value-based methods have been widely used to solve similar problems, we adopt an actor-critic based direct policy search method framed in a temporal difference learning approach. Successful behavior learning is challenging in large state and/or action spaces, requiring many trials. We introduce a partial policy-based reinforcement learning to enable solving the large problem of localization by learning the optimal policy on smaller partial domains. Independent actors efficiently learn the corresponding partial policies, each utilizing their own independent critic. The proposed policy reconstruction from the partial policies ensures a robust and efficient localization utilizing the sub-agents solving simple binary decision problems in their corresponding partial action spaces. The proposed reinforcement learning requires a small number of trials to learn the optimal behavior compared with the original behavior learning scheme.