 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel orthogonalization and Bayesian forecast mixing via Principal Component Analysis
May 17, 2024
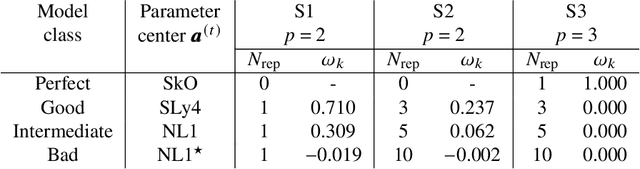


One can improve predictability in the unknown domain by combining forecasts of imperfect complex computational models using a Bayesian statistical machine learning framework. In many cases, however, the models used in the mixing process are similar. In addition to contaminating the model space, the existence of such similar, or even redundant, models during the multimodeling process can result in misinterpretation of results and deterioration of predictive performance. In this work we describe a method based on the Principal Component Analysis that eliminates model redundancy. We show that by adding model orthogonalization to the proposed Bayesian Model Combination framework, one can arrive at better prediction accuracy and reach excellent uncertainty quantification performance.
Local Bayesian Dirichlet mixing of imperfect models
Nov 02, 2023To improve the predictability of complex computational models in the experimentally-unknown domains, we propose a Bayesian statistical machine learning framework utilizing the Dirichlet distribution that combines results of several imperfect models. This framework can be viewed as an extension of Bayesian stacking. To illustrate the method, we study the ability of Bayesian model averaging and mixing techniques to mine nuclear masses. We show that the global and local mixtures of models reach excellent performance on both prediction accuracy and uncertainty quantification and are preferable to classical Bayesian model averaging. Additionally, our statistical analysis indicates that improving model predictions through mixing rather than mixing of corrected models leads to more robust extrapolations.
Variational Inference with Vine Copulas: An efficient Approach for Bayesian Computer Model Calibration
Mar 28, 2020



With the advancements of computer architectures, the use of computational models proliferates to solve complex problems in many scientific applications such as nuclear physics and climate research. However, the potential of such models is often hindered because they tend to be computationally expensive and consequently ill-fitting for uncertainty quantification. Furthermore, they are usually not calibrated with real-time observations. We develop a computationally efficient algorithm based on variational Bayes inference (VBI) for calibration of computer models with Gaussian processes. Unfortunately, the speed and scalability of VBI diminishes when applied to the calibration framework with dependent data. To preserve the efficiency of VBI, we adopt a pairwise decomposition of the data likelihood using vine copulas that separate the information on dependence structure in data from their marginal distributions. We provide both theoretical and empirical evidence for the computational scalability of our methodology and describe all the necessary details for an efficient implementation of the proposed algorithm. We also demonstrated the opportunities given by our method for practitioners on a real data example through calibration of the Liquid Drop Model of nuclear binding energies.
Statistical aspects of nuclear mass models
Feb 11, 2020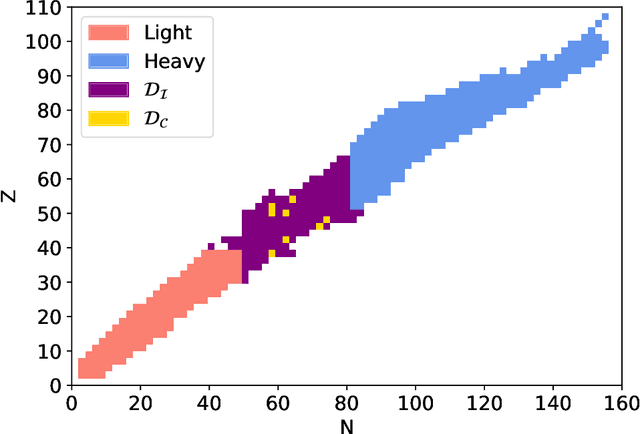

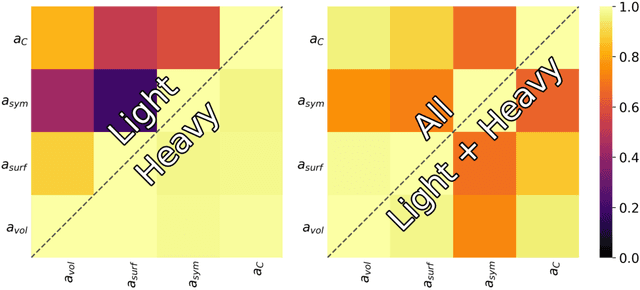

We study the information content of nuclear masses from the perspective of global models of nuclear binding energies. To this end, we employ a number of statistical methods and diagnostic tools, including Bayesian calibration, Bayesian model averaging, chi-square correlation analysis, principal component analysis, and empirical coverage probability. Using Bayesian framework, we investigate the structure of the 4-parameter Liquid Drop Model by considering discrepant mass domains for calibration. We then use the chi-square correlation framework to analyze the 14-parameter Skyrme energy density functional calibrated using homogeneous and heterogeneous datasets. We show that a quite dramatic parameter reduction can be achieved in both cases. The advantage of the Bayesian model averaging for improving the uncertainty quantification is demonstrated. The statistical approaches used are pedagogically described; in this context this work can serve as a guide for future applications.