 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocabulary Transfer for Medical Texts
Aug 04, 2022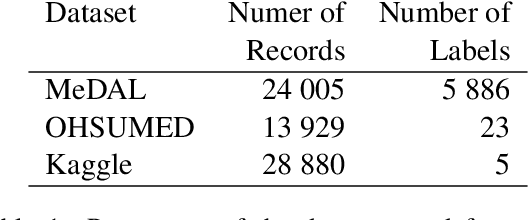
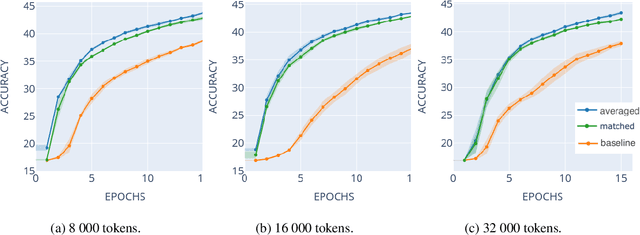

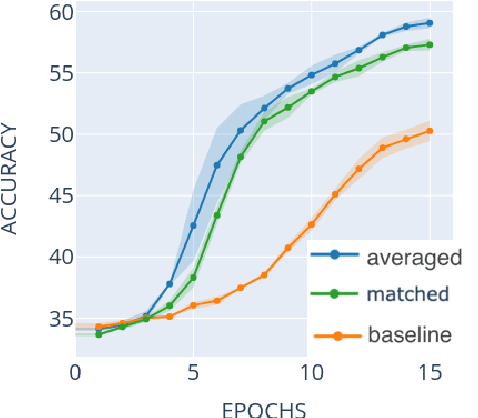
Vocabulary transfer is a transfer learning subtask in which language models fine-tune with the corpus-specific tokenization instead of the default one, which is being used during pretraining. This usually improves the resulting performance of the model, and in the paper, we demonstrate that vocabulary transfer is especially beneficial for medical text processing. Using three different medical natural language processing datasets, we show vocabulary transfer to provide up to ten extra percentage points for the downstream classifier accuracy.
Do Data-based Curricula Work?
Dec 13, 2021



Current state-of-the-art NLP systems use large neural networks that require lots of computational resources for training. Inspired by human knowledge acquisition, researchers have proposed curriculum learning, - sequencing of tasks (task-based curricula) or ordering and sampling of the datasets (data-based curricula) that facilitate training. This work investigates the benefits of data-based curriculum learning for large modern language models such as BERT and T5. We experiment with various curricula based on a range of complexity measures and different sampling strategies. Extensive experiments on different NLP tasks show that curricula based on various complexity measures rarely has any benefits while random sampling performs either as well or better than curricula.