Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Recognition From Speech With Recurrent Neural Networks
Jul 05, 2018


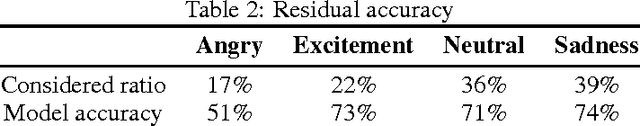
In this paper the task of emotion recognition from speech is considered. Proposed approach uses deep recurrent neural network trained on a sequence of acoustic features calculated over small speech intervals. At the same time special probabilistic-nature CTC loss function allows to consider long utterances containing both emotional and neutral parts. The effectiveness of such an approach is shown in two ways. Firstly, the comparison with recent advances in this field is carried out. Secondly, human performance on the same task is measured. Both criteria show the high quality of the proposed method.
Via