 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABCinML: Anticipatory Bias Correction in Machine Learning Applications
Jun 14, 2022
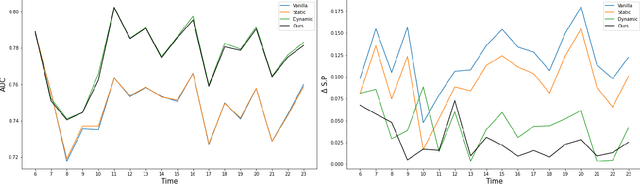


The idealization of a static machine-learned model, trained once and deployed forever, is not practical. As input distributions change over time, the model will not only lose accuracy, any constraints to reduce bias against a protected class may fail to work as intended. Thus, researchers have begun to explore ways to maintain algorithmic fairness over time. One line of work focuses on dynamic learning: retraining after each batch, and the other on robust learning which tries to make algorithms robust against all possible future changes. Dynamic learning seeks to reduce biases soon after they have occurred and robust learning often yields (overly) conservative models. We propose an anticipatory dynamic learning approach for correcting the algorithm to mitigate bias before it occurs. Specifically, we make use of anticipations regarding the relative distributions of population subgroups (e.g., relative ratios of male and female applicants) in the next cycle to identify the right parameters for an importance weighing fairness approach. Results from experiments over multiple real-world datasets suggest that this approach has promise for anticipatory bias correction.
Balancing Fairness and Accuracy in Sentiment Detection using Multiple Black Box Models
Apr 22, 2022



Sentiment detection is an important building block for multiple information retrieval tasks such as product recommendation, cyberbullying detection, and misinformation detection. Unsurprisingly, multiple commercial APIs, each with different levels of accuracy and fairness, are now available for sentiment detection. While combining inputs from multiple modalities or black-box models for increasing accuracy is commonly studied in multimedia computing literature, there has been little work on combining different modalities for increasing fairness of the resulting decision. In this work, we audit multiple commercial sentiment detection APIs for the gender bias in two actor news headlines settings and report on the level of bias observed. Next, we propose a "Flexible Fair Regression" approach, which ensures satisfactory accuracy and fairness by jointly learning from multiple black-box models. The results pave way for fair yet accurate sentiment detectors for multiple applications.
Quantifying Algorithmic Biases over Time
Jul 02, 2019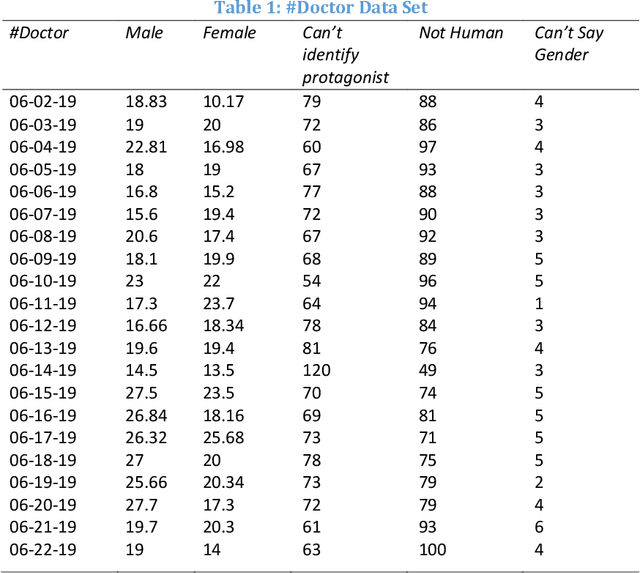


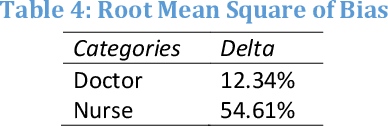
Algorithms now permeate multiple aspects of human lives and multiple recent results have reported that these algorithms may have biases pertaining to gender, race, and other demographic characteristics. The metrics used to quantify such biases have still focused on a static notion of algorithms. However, algorithms evolve over time. For instance, Tay (a conversational bot launched by Microsoft) was arguably not biased at its launch but quickly became biased, sexist, and racist over time. We suggest a set of intuitive metrics to study the variations in biases over time and present the results for a case study for genders represented in images resulting from a Twitter image search for #Nurse and #Doctor over a period of 21 days. Results indicate that biases vary significantly over time and the direction of bias could appear to be different on different days. Hence, one-shot measurements may not suffice for understanding algorithmic bias, thus motivating further work on studying biases in algorithms over time.