 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThematically Reinforced Explicit Semantic Analysis
May 17, 2014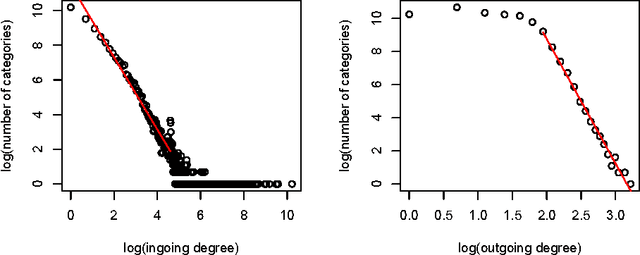
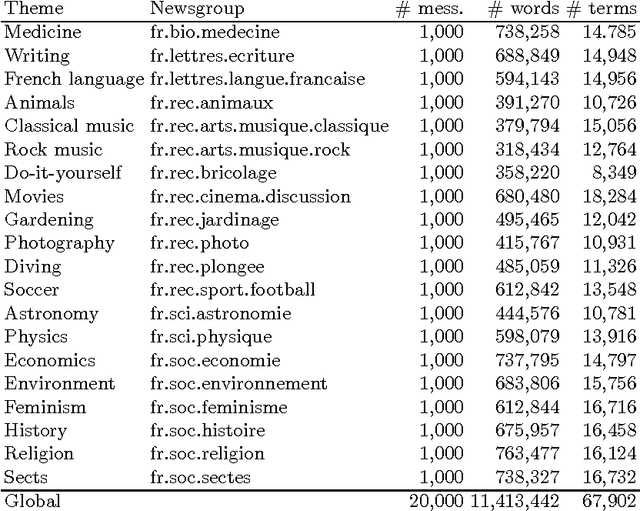
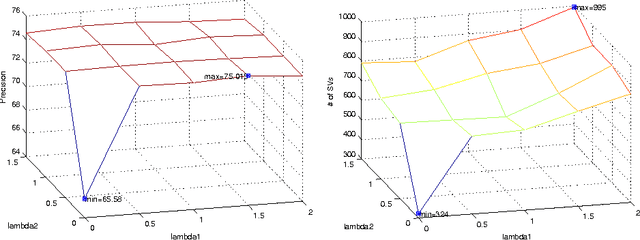
We present an extended, thematically reinforced version of Gabrilovich and Markovitch's Explicit Semantic Analysis (ESA), where we obtain thematic information through the category structure of Wikipedia. For this we first define a notion of categorical tfidf which measures the relevance of terms in categories. Using this measure as a weight we calculate a maximal spanning tree of the Wikipedia corpus considered as a directed graph of pages and categories. This tree provides us with a unique path of "most related categories" between each page and the top of the hierarchy. We reinforce tfidf of words in a page by aggregating it with categorical tfidfs of the nodes of these paths, and define a thematically reinforced ESA semantic relatedness measure which is more robust than standard ESA and less sensitive to noise caused by out-of-context words. We apply our method to the French Wikipedia corpus, evaluate it through a text classification on a 37.5 MB corpus of 20 French newsgroups and obtain a precision increase of 9-10% compared with standard ESA.
* 13 pages, 2 figures, presented at CICLing 2013
Wikipedia Arborification and Stratified Explicit Semantic Analysis
Feb 01, 2012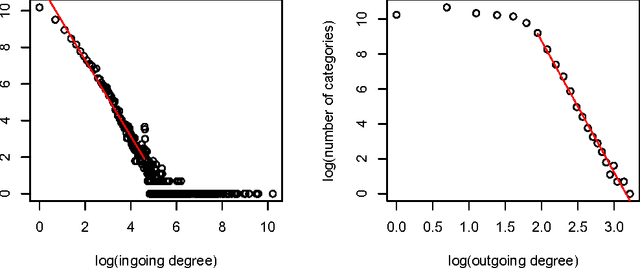
[This is the translation of paper "Arborification de Wikip\'edia et analyse s\'emantique explicite stratifi\'ee" submitted to TALN 2012.] We present an extension of the Explicit Semantic Analysis method by Gabrilovich and Markovitch. Using their semantic relatedness measure, we weight the Wikipedia categories graph. Then, we extract a minimal spanning tree, using Chu-Liu & Edmonds' algorithm. We define a notion of stratified tfidf where the stratas, for a given Wikipedia page and a given term, are the classical tfidf and categorical tfidfs of the term in the ancestor categories of the page (ancestors in the sense of the minimal spanning tree). Our method is based on this stratified tfidf, which adds extra weight to terms that "survive" when climbing up the category tree. We evaluate our method by a text classification on the WikiNews corpus: it increases precision by 18%. Finally, we provide hints for future research
Query Expansion: Term Selection using the EWC Semantic Relatedness Measure
Aug 19, 2011
This paper investigates the efficiency of the EWC semantic relatedness measure in an ad-hoc retrieval task. This measure combines the Wikipedia-based Explicit Semantic Analysis measure, the WordNet path measure and the mixed collocation index. In the experiments, the open source search engine Terrier was utilised as a tool to index and retrieve data. The proposed technique was tested on the NTCIR data collection. The experiments demonstrated promising results.
* 5 pages, 1 figure, accepted at ASIR'11 <http://fedcsis.org/?q=node/62>
A Semantic Relatedness Measure Based on Combined Encyclopedic, Ontological and Collocational Knowledge
Aug 19, 2011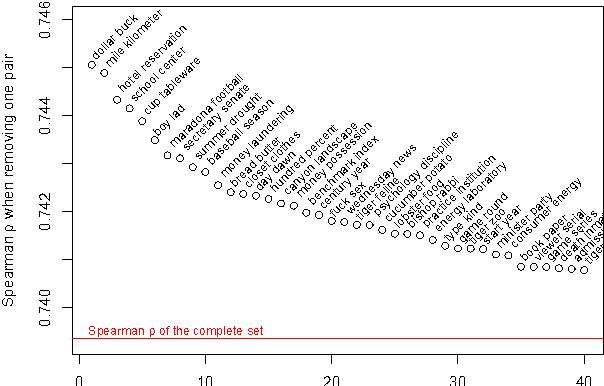
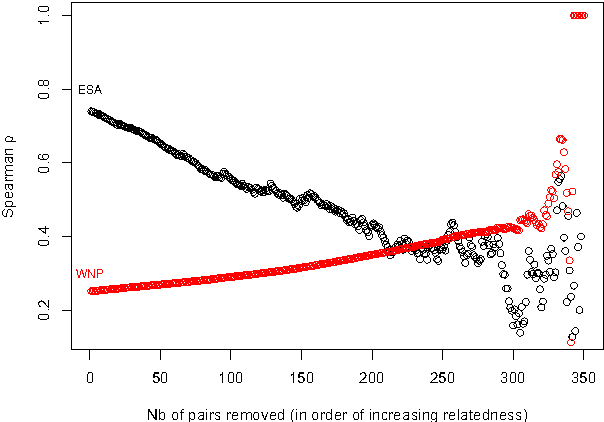
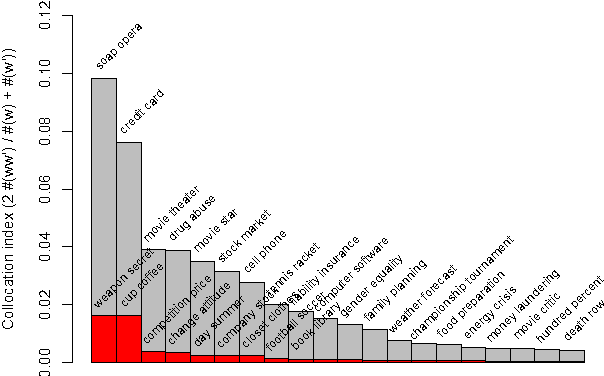
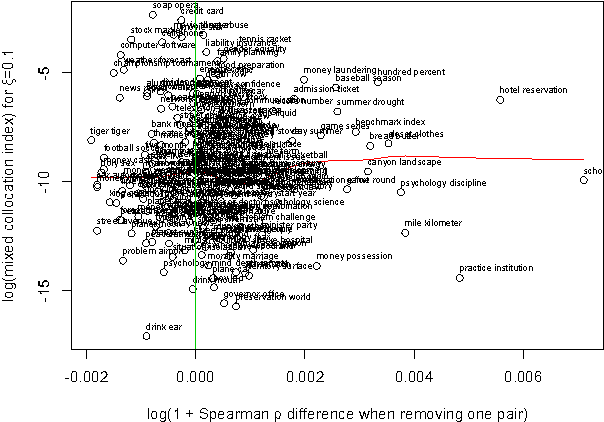
We describe a new semantic relatedness measure combining the Wikipedia-based Explicit Semantic Analysis measure, the WordNet path measure and the mixed collocation index. Our measure achieves the currently highest results on the WS-353 test: a Spearman rho coefficient of 0.79 (vs. 0.75 in (Gabrilovich and Markovitch, 2007)) when applying the measure directly, and a value of 0.87 (vs. 0.78 in (Agirre et al., 2009)) when using the prediction of a polynomial SVM classifier trained on our measure. In the appendix we discuss the adaptation of ESA to 2011 Wikipedia data, as well as various unsuccessful attempts to enhance ESA by filtering at word, sentence, and section level.
* 6 pages, 6 figures, accepted for publication at IJCNLP2011 Conference