 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhittle Index Learning Algorithms for Restless Bandits with Constant Stepsizes
Sep 06, 2024



We study the Whittle index learning algorithm for restless multi-armed bandits. We consider index learning algorithm with Q-learning. We first present Q-learning algorithm with exploration policies -- epsilon-greedy, softmax, epsilon-softmax with constant stepsizes. We extend the study of Q-learning to index learning for single-armed restless bandit. The algorithm of index learning is two-timescale variant of stochastic approximation, on slower timescale we update index learning scheme and on faster timescale we update Q-learning assuming fixed index value. In Q-learning updates are in asynchronous manner. We study constant stepsizes two timescale stochastic approximation algorithm. We provide analysis of two-timescale stochastic approximation for index learning with constant stepsizes. Further, we present study on index learning with deep Q-network (DQN) learning and linear function approximation with state-aggregation method. We describe the performance of our algorithms using numerical examples. We have shown that index learning with Q learning, DQN and function approximations learns the Whittle index.
Indexability of Finite State Restless Multi-Armed Bandit and Rollout Policy
Apr 30, 2023
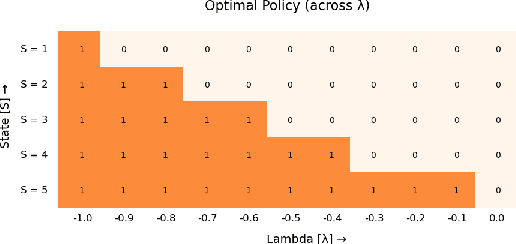
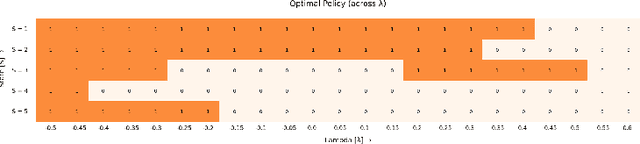

We consider finite state restless multi-armed bandit problem. The decision maker can act on M bandits out of N bandits in each time step. The play of arm (active arm) yields state dependent rewards based on action and when the arm is not played, it also provides rewards based on the state and action. The objective of the decision maker is to maximize the infinite horizon discounted reward. The classical approach to restless bandits is Whittle index policy. In such policy, the M arms with highest indices are played at each time step. Here, one decouples the restless bandits problem by analyzing relaxed constrained restless bandits problem. Then by Lagrangian relaxation problem, one decouples restless bandits problem into N single-armed restless bandit problems. We analyze the single-armed restless bandit. In order to study the Whittle index policy, we show structural results on the single armed bandit model. We define indexability and show indexability in special cases. We propose an alternative approach to verify the indexable criteria for a single armed bandit model using value iteration algorithm. We demonstrate the performance of our algorithm with different examples. We provide insight on condition of indexability of restless bandits using different structural assumptions on transition probability and reward matrices. We also study online rollout policy and discuss the computation complexity of algorithm and compare that with complexity of index computation. Numerical examples illustrate that index policy and rollout policy performs better than myopic policy.