 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionNet: 3D Object Classification Using Multiple Data Representations
Nov 27, 2016
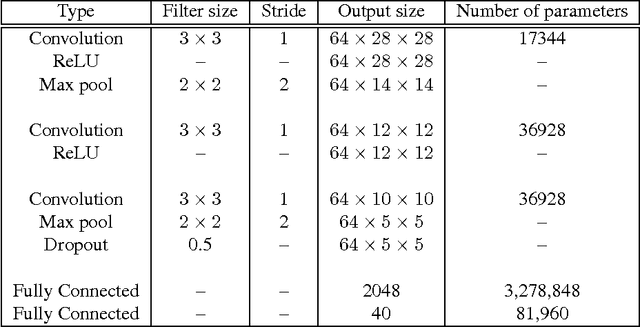
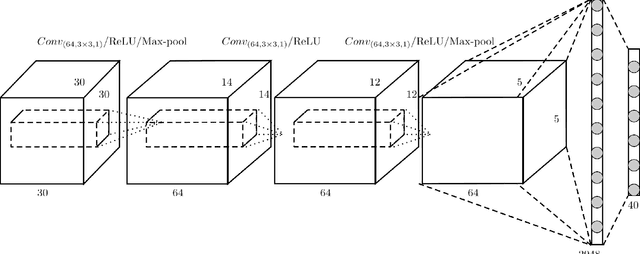
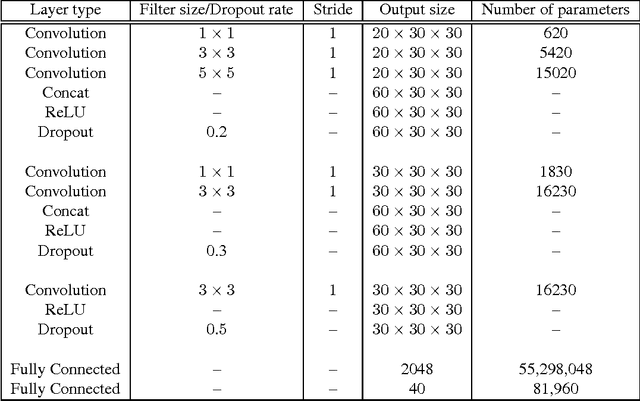
High-quality 3D object recognition is an important component of many vision and robotics systems. We tackle the object recognition problem using two data representations, to achieve leading results on the Princeton ModelNet challenge. The two representations: 1. Volumetric representation: the 3D object is discretized spatially as binary voxels - $1$ if the voxel is occupied and $0$ otherwise. 2. Pixel representation: the 3D object is represented as a set of projected 2D pixel images. Current leading submissions to the ModelNet Challenge use Convolutional Neural Networks (CNNs) on pixel representations. However, we diverge from this trend and additionally, use Volumetric CNNs to bridge the gap between the efficiency of the above two representations. We combine both representations and exploit them to learn new features, which yield a significantly better classifier than using either of the representations in isolation. To do this, we introduce new Volumetric CNN (V-CNN) architectures.