 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Processing of Aviation Occurrence Reports for Safety Management
Jan 13, 2023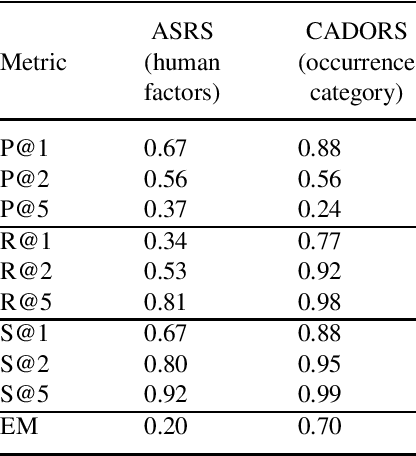
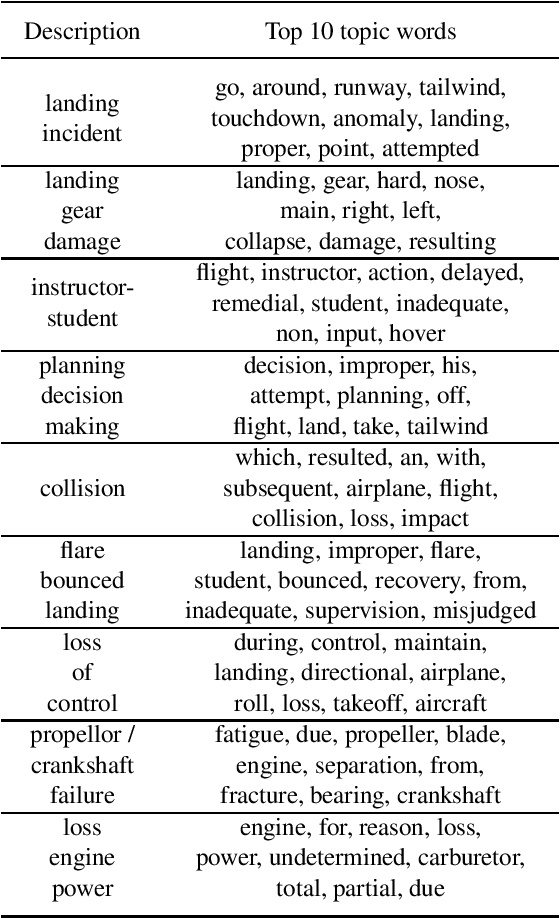
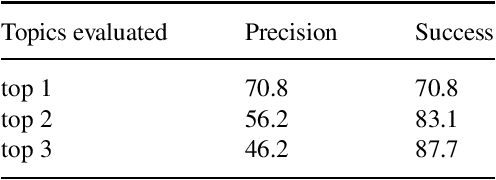

Occurrence reporting is a commonly used method in safety management systems to obtain insight in the prevalence of hazards and accident scenarios. In support of safety data analysis, reports are often categorized according to a taxonomy. However, the processing of the reports can require significant effort from safety analysts and a common problem is interrater variability in labeling processes. Also, in some cases, reports are not processed according to a taxonomy, or the taxonomy does not fully cover the contents of the documents. This paper explores various Natural Language Processing (NLP) methods to support the analysis of aviation safety occurrence reports. In particular, the problems studied are the automatic labeling of reports using a classification model, extracting the latent topics in a collection of texts using a topic model and the automatic generation of probable cause texts. Experimental results showed that (i) under the right conditions the labeling of occurrence reports can be effectively automated with a transformer-based classifier, (ii) topic modeling can be useful for finding the topics present in a collection of reports, and (iii) using a summarization model can be a promising direction for generating probable cause texts.