 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISMe: A Novel LLM-Powered Tool for Interactive Privacy Policy Assessment
Jan 27, 2025
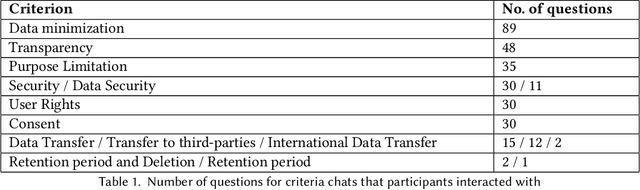
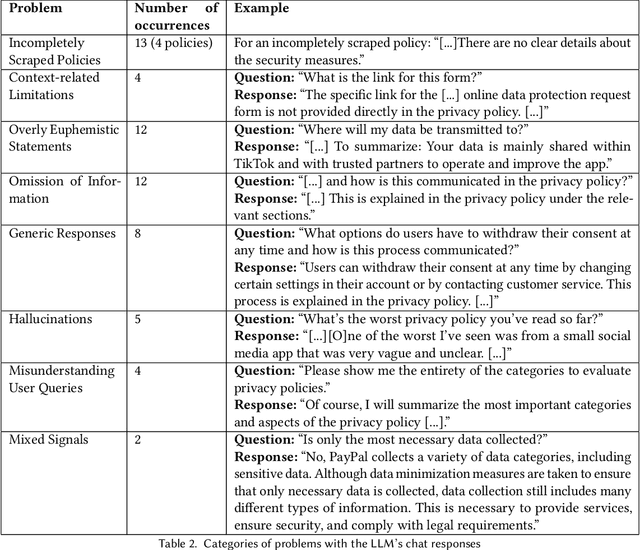
Protecting online privacy requires users to engage with and comprehend website privacy policies, but many policies are difficult and tedious to read. We present PRISMe (Privacy Risk Information Scanner for Me), a novel Large Language Model (LLM)-driven privacy policy assessment tool, which helps users to understand the essence of a lengthy, complex privacy policy while browsing. The tool, a browser extension, integrates a dashboard and an LLM chat. One major contribution is the first rigorous evaluation of such a tool. In a mixed-methods user study (N=22), we evaluate PRISMe's efficiency, usability, understandability of the provided information, and impacts on awareness. While our tool improves privacy awareness by providing a comprehensible quick overview and a quality chat for in-depth discussion, users note issues with consistency and building trust in the tool. From our insights, we derive important design implications to guide future policy analysis tools.
Legally Binding but Unfair? Towards Assessing Fairness of Privacy Policies
Mar 12, 2024

Privacy policies are expected to inform data subjects about their data protection rights. They should explain the data controller's data management practices, and make facts such as retention periods or data transfers to third parties transparent. Privacy policies only fulfill their purpose, if they are correctly perceived, interpreted, understood, and trusted by the data subject. Amongst others, this requires that a privacy policy is written in a fair way, e.g., it does not use polarizing terms, does not require a certain education, or does not assume a particular social background. In this work-in-progress paper, we outline our approach to assessing fairness in privacy policies. To this end, we identify from fundamental legal sources and fairness research, how the dimensions informational fairness, representational fairness and ethics/morality are related to privacy policies. We propose options to automatically assess policies in these fairness dimensions, based on text statistics, linguistic methods and artificial intelligence. Finally, we conduct initial experiments with German privacy policies to provide evidence that our approach is applicable. Our experiments indicate that there are indeed issues in all three dimensions of fairness. For example, our approach finds out if a policy discriminates against individuals with impaired reading skills or certain demographics, and identifies questionable ethics. This is important, as future privacy policies may be used in a corpus for legal artificial intelligence models.
Fairness Certification for Natural Language Processing and Large Language Models
Jan 03, 2024Natural Language Processing (NLP) plays an important role in our daily lives, particularly due to the enormous progress of Large Language Models (LLM). However, NLP has many fairness-critical use cases, e.g., as an expert system in recruitment or as an LLM-based tutor in education. Since NLP is based on human language, potentially harmful biases can diffuse into NLP systems and produce unfair results, discriminate against minorities or generate legal issues. Hence, it is important to develop a fairness certification for NLP approaches. We follow a qualitative research approach towards a fairness certification for NLP. In particular, we have reviewed a large body of literature on algorithmic fairness, and we have conducted semi-structured expert interviews with a wide range of experts from that area. We have systematically devised six fairness criteria for NLP, which can be further refined into 18 sub-categories. Our criteria offer a foundation for operationalizing and testing processes to certify fairness, both from the perspective of the auditor and the audited organization.