 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to the Future: Joint Aware Temporal Deep Learning 3D Human Pose Estimation
Feb 22, 2020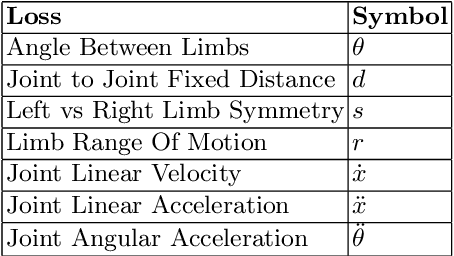


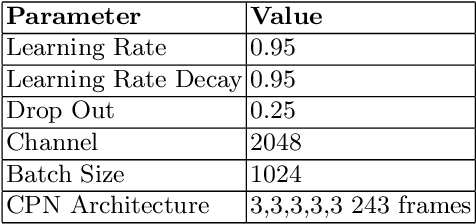
We propose a new deep learning network that introduces a deeper CNN channel filter and constraints as losses to reduce joint position and motion errors for 3D video human body pose estimation. Our model outperforms the previous best result from the literature based on mean per-joint position error, velocity error, and acceleration errors on the Human 3.6M benchmark corresponding to a new state-of-the-art mean error reduction in all protocols and motion metrics. Mean per joint error is reduced by 1%, velocity error by 7% and acceleration by 13% compared to the best results from the literature. Our contribution increasing positional accuracy and motion smoothness in video can be integrated with future end to end networks without increasing network complexity. Our model and code are available at https://vnmr.github.io/ Keywords: 3D, human, image, pose, action, detection, object, video, visual, supervised, joint, kinematic
Uncalibrated Deflectometry with a Mobile Device on Extended Specular Surfaces
Jul 24, 2019
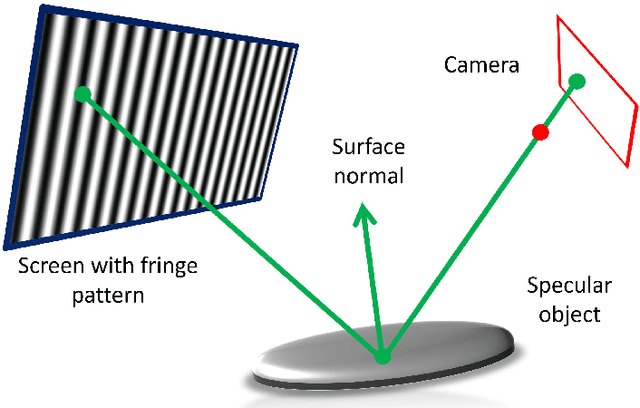


We introduce a system and methods for the three-dimensional measurement of extended specular surfaces with high surface normal variations. Our system consists only of a mobile hand held device and exploits screen and front camera for Deflectometry-based surface measurements. We demonstrate high quality measurements without the need for an offline calibration procedure. In addition, we develop a multi-view technique to compensate for the small screen of a mobile device so that large surfaces can be densely reconstructed in their entirety. This work is a first step towards developing a self-calibrating Deflectometry procedure capable of taking 3D surface measurements of specular objects in the wild and accessible to users with little to no technical imaging experience.
Automatic Trimap Generation for Image Matting
Jul 04, 2017


Image matting is a longstanding problem in computational photography. Although, it has been studied for more than two decades, yet there is a challenge of developing an automatic matting algorithm which does not require any human efforts. Most of the state-of-the-art matting algorithms require human intervention in the form of trimap or scribbles to generate the alpha matte form the input image. In this paper, we present a simple and efficient approach to automatically generate the trimap from the input image and make the whole matting process free from human-in-the-loop. We use learning based matting method to generate the matte from the automatically generated trimap. Experimental results demonstrate that our method produces good quality trimap which results into accurate matte estimation. We validate our results by replacing the automatically generated trimap by manually created trimap while using the same image matting algorithm.