 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRhetorical Role Labeling of Legal Documents using Transformers and Graph Neural Networks
May 06, 2023A legal document is usually long and dense requiring human effort to parse it. It also contains significant amounts of jargon which make deriving insights from it using existing models a poor approach. This paper presents the approaches undertaken to perform the task of rhetorical role labelling on Indian Court Judgements as part of SemEval Task 6: understanding legal texts, shared subtask A. We experiment with graph based approaches like Graph Convolutional Networks and Label Propagation Algorithm, and transformer-based approaches including variants of BERT to improve accuracy scores on text classification of complex legal documents.
BITS Pilani at HinglishEval: Quality Evaluation for Code-Mixed Hinglish Text Using Transformers
Jun 17, 2022
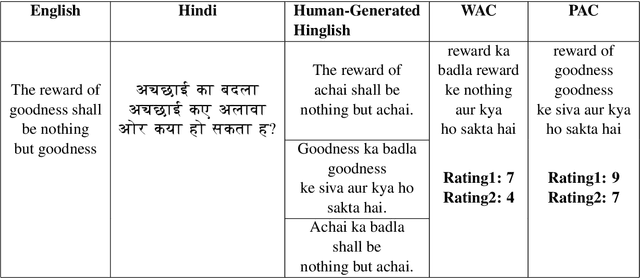
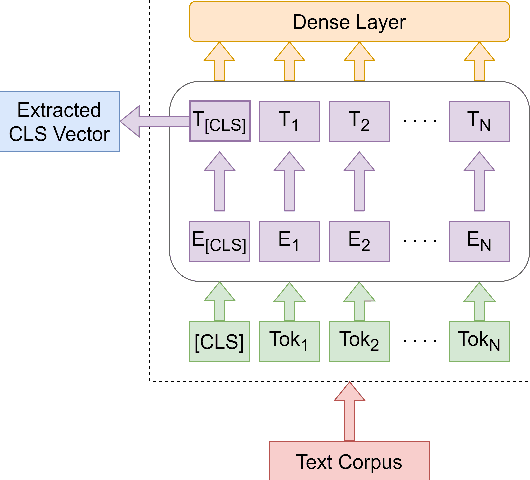

Code-Mixed text data consists of sentences having words or phrases from more than one language. Most multi-lingual communities worldwide communicate using multiple languages, with English usually one of them. Hinglish is a Code-Mixed text composed of Hindi and English but written in Roman script. This paper aims to determine the factors influencing the quality of Code-Mixed text data generated by the system. For the HinglishEval task, the proposed model uses multi-lingual BERT to find the similarity between synthetically generated and human-generated sentences to predict the quality of synthetically generated Hinglish sentences.