 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBruSLeAttack: A Query-Efficient Score-Based Black-Box Sparse Adversarial Attack
Apr 08, 2024We study the unique, less-well understood problem of generating sparse adversarial samples simply by observing the score-based replies to model queries. Sparse attacks aim to discover a minimum number-the l0 bounded-perturbations to model inputs to craft adversarial examples and misguide model decisions. But, in contrast to query-based dense attack counterparts against black-box models, constructing sparse adversarial perturbations, even when models serve confidence score information to queries in a score-based setting, is non-trivial. Because, such an attack leads to i) an NP-hard problem; and ii) a non-differentiable search space. We develop the BruSLeAttack-a new, faster (more query-efficient) Bayesian algorithm for the problem. We conduct extensive attack evaluations including an attack demonstration against a Machine Learning as a Service (MLaaS) offering exemplified by Google Cloud Vision and robustness testing of adversarial training regimes and a recent defense against black-box attacks. The proposed attack scales to achieve state-of-the-art attack success rates and query efficiency on standard computer vision tasks such as ImageNet across different model architectures. Our artefacts and DIY attack samples are available on GitHub. Importantly, our work facilitates faster evaluation of model vulnerabilities and raises our vigilance on the safety, security and reliability of deployed systems.
Query Efficient Decision Based Sparse Attacks Against Black-Box Deep Learning Models
Jan 31, 2022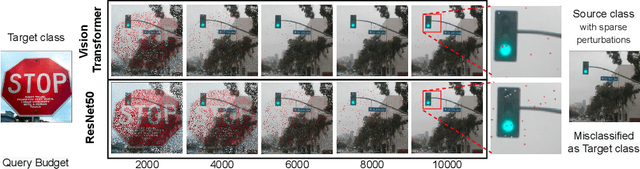

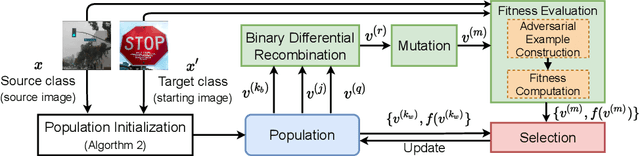
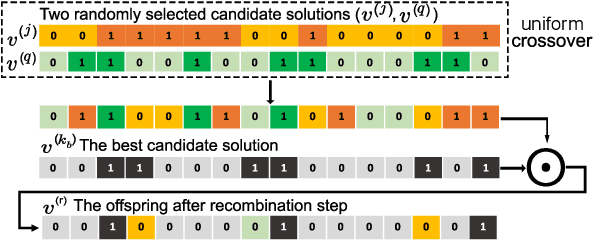
Despite our best efforts, deep learning models remain highly vulnerable to even tiny adversarial perturbations applied to the inputs. The ability to extract information from solely the output of a machine learning model to craft adversarial perturbations to black-box models is a practical threat against real-world systems, such as autonomous cars or machine learning models exposed as a service (MLaaS). Of particular interest are sparse attacks. The realization of sparse attacks in black-box models demonstrates that machine learning models are more vulnerable than we believe. Because these attacks aim to minimize the number of perturbed pixels measured by l_0 norm-required to mislead a model by solely observing the decision (the predicted label) returned to a model query; the so-called decision-based attack setting. But, such an attack leads to an NP-hard optimization problem. We develop an evolution-based algorithm-SparseEvo-for the problem and evaluate against both convolutional deep neural networks and vision transformers. Notably, vision transformers are yet to be investigated under a decision-based attack setting. SparseEvo requires significantly fewer model queries than the state-of-the-art sparse attack Pointwise for both untargeted and targeted attacks. The attack algorithm, although conceptually simple, is also competitive with only a limited query budget against the state-of-the-art gradient-based whitebox attacks in standard computer vision tasks such as ImageNet. Importantly, the query efficient SparseEvo, along with decision-based attacks, in general, raise new questions regarding the safety of deployed systems and poses new directions to study and understand the robustness of machine learning models.
RamBoAttack: A Robust Query Efficient Deep Neural Network Decision Exploit
Dec 10, 2021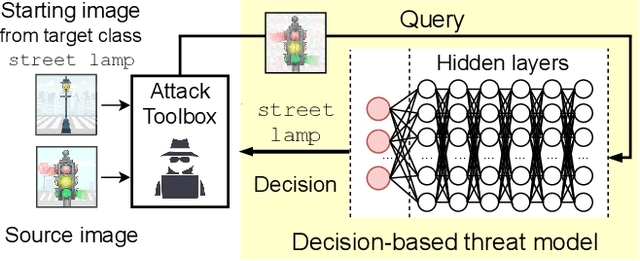
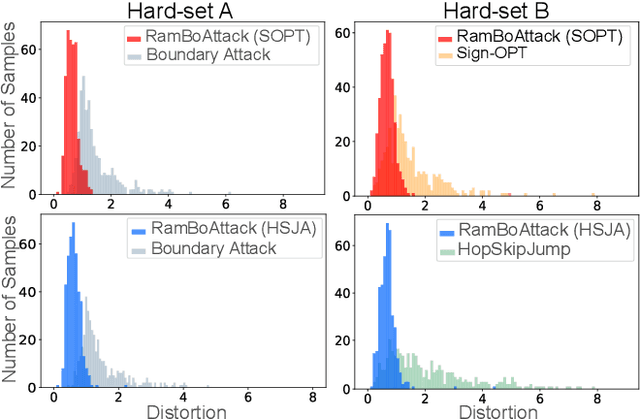
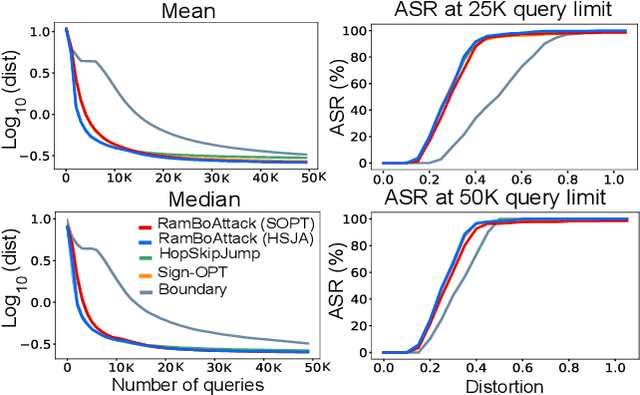
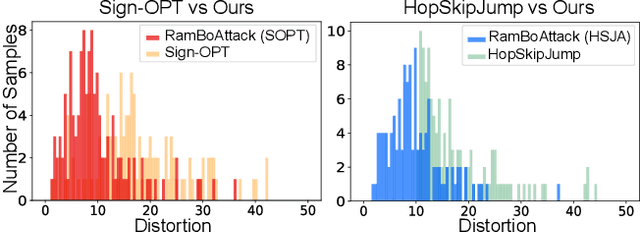
Machine learning models are critically susceptible to evasion attacks from adversarial examples. Generally, adversarial examples, modified inputs deceptively similar to the original input, are constructed under whitebox settings by adversaries with full access to the model. However, recent attacks have shown a remarkable reduction in query numbers to craft adversarial examples using blackbox attacks. Particularly, alarming is the ability to exploit the classification decision from the access interface of a trained model provided by a growing number of Machine Learning as a Service providers including Google, Microsoft, IBM and used by a plethora of applications incorporating these models. The ability of an adversary to exploit only the predicted label from a model to craft adversarial examples is distinguished as a decision-based attack. In our study, we first deep dive into recent state-of-the-art decision-based attacks in ICLR and SP to highlight the costly nature of discovering low distortion adversarial employing gradient estimation methods. We develop a robust query efficient attack capable of avoiding entrapment in a local minimum and misdirection from noisy gradients seen in gradient estimation methods. The attack method we propose, RamBoAttack, exploits the notion of Randomized Block Coordinate Descent to explore the hidden classifier manifold, targeting perturbations to manipulate only localized input features to address the issues of gradient estimation methods. Importantly, the RamBoAttack is more robust to the different sample inputs available to an adversary and the targeted class. Overall, for a given target class, RamBoAttack is demonstrated to be more robust at achieving a lower distortion within a given query budget. We curate our extensive results using the large-scale high-resolution ImageNet dataset and open-source our attack, test samples and artifacts on GitHub.