 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRamBoAttack: A Robust Query Efficient Deep Neural Network Decision Exploit
Paper and Code
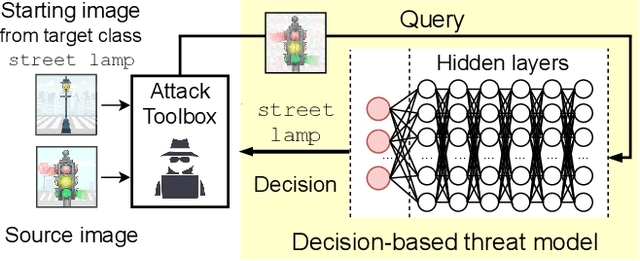
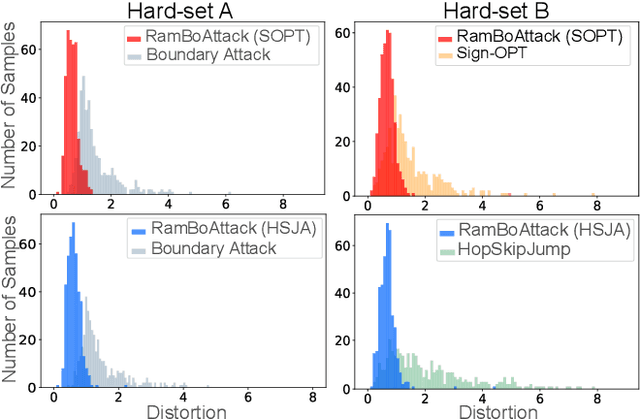
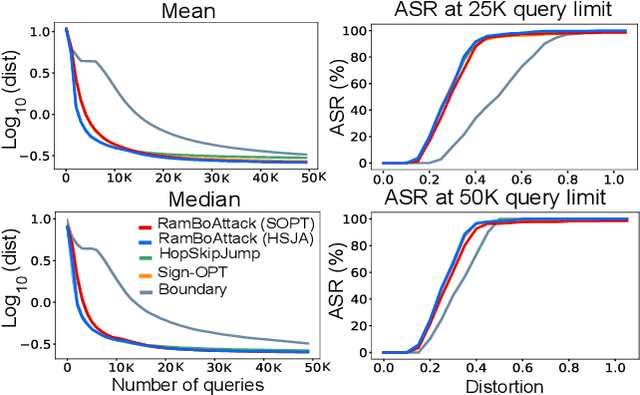
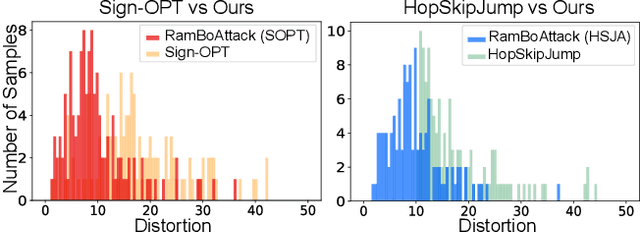
Machine learning models are critically susceptible to evasion attacks from adversarial examples. Generally, adversarial examples, modified inputs deceptively similar to the original input, are constructed under whitebox settings by adversaries with full access to the model. However, recent attacks have shown a remarkable reduction in query numbers to craft adversarial examples using blackbox attacks. Particularly, alarming is the ability to exploit the classification decision from the access interface of a trained model provided by a growing number of Machine Learning as a Service providers including Google, Microsoft, IBM and used by a plethora of applications incorporating these models. The ability of an adversary to exploit only the predicted label from a model to craft adversarial examples is distinguished as a decision-based attack. In our study, we first deep dive into recent state-of-the-art decision-based attacks in ICLR and SP to highlight the costly nature of discovering low distortion adversarial employing gradient estimation methods. We develop a robust query efficient attack capable of avoiding entrapment in a local minimum and misdirection from noisy gradients seen in gradient estimation methods. The attack method we propose, RamBoAttack, exploits the notion of Randomized Block Coordinate Descent to explore the hidden classifier manifold, targeting perturbations to manipulate only localized input features to address the issues of gradient estimation methods. Importantly, the RamBoAttack is more robust to the different sample inputs available to an adversary and the targeted class. Overall, for a given target class, RamBoAttack is demonstrated to be more robust at achieving a lower distortion within a given query budget. We curate our extensive results using the large-scale high-resolution ImageNet dataset and open-source our attack, test samples and artifacts on GitHub.