 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulticopy Reinforcement Learning Agents
Sep 19, 2023
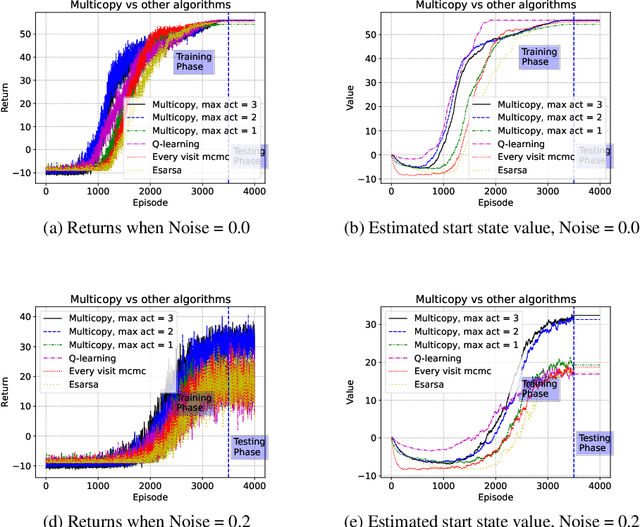
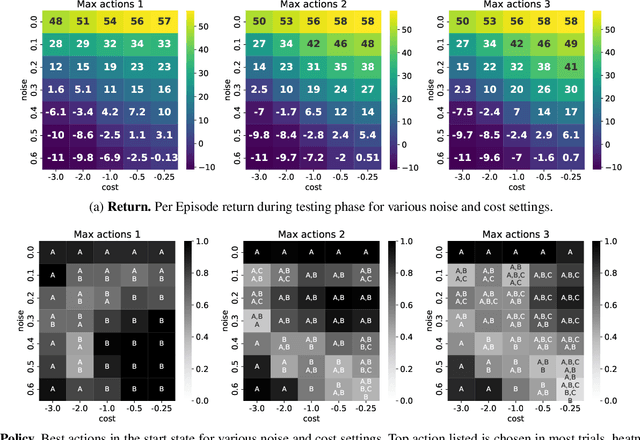
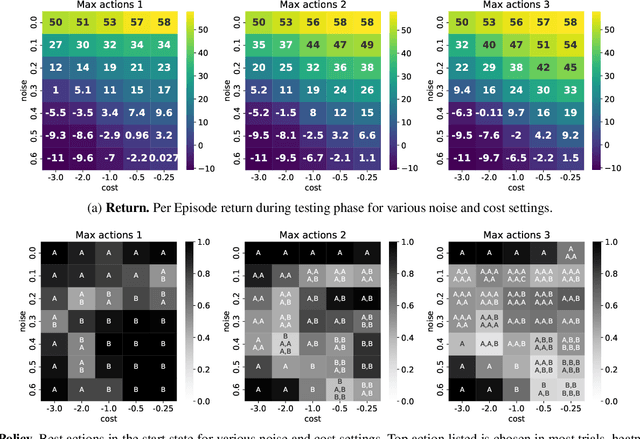
This paper examines a novel type of multi-agent problem, in which an agent makes multiple identical copies of itself in order to achieve a single agent task better or more efficiently. This strategy improves performance if the environment is noisy and the task is sometimes unachievable by a single agent copy. We propose a learning algorithm for this multicopy problem which takes advantage of the structure of the value function to efficiently learn how to balance the advantages and costs of adding additional copies.
Learning to Route in Mobile Wireless Networks
Jul 23, 2022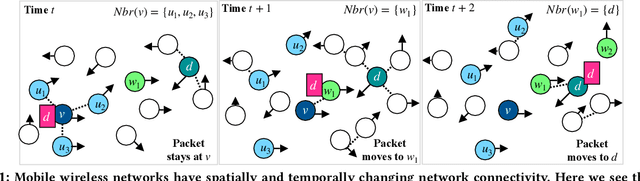



Designing effective routing strategies for mobile wireless networks is challenging due to the need to seamlessly adapt routing behavior to spatially diverse and temporally changing network conditions. In this work, we use deep reinforcement learning (DeepRL) to learn a scalable and generalizable single-copy routing strategy for such networks. We make the following contributions: i) we design a reward function that enables the DeepRL agent to explicitly trade-off competing network goals, such as minimizing delay vs. the number of transmissions per packet; ii) we propose a novel set of relational neighborhood, path, and context features to characterize mobile wireless networks and model device mobility independently of a specific network topology; and iii) we use a flexible training approach that allows us to combine data from all packets and devices into a single offline centralized training set to train a single DeepRL agent. To evaluate generalizeability and scalability, we train our DeepRL agent on one mobile network scenario and then test it on other mobile scenarios, varying the number of devices and transmission ranges. Our results show our learned single-copy routing strategy outperforms all other strategies in terms of delay except for the optimal strategy, even on scenarios on which the DeepRL agent was not trained.
Relational Deep Reinforcement Learning for Routing in Wireless Networks
Dec 31, 2020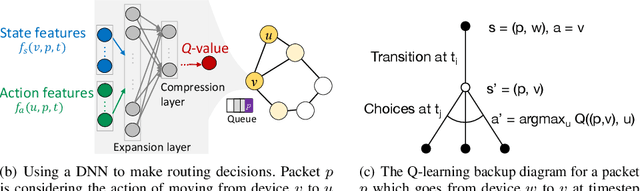
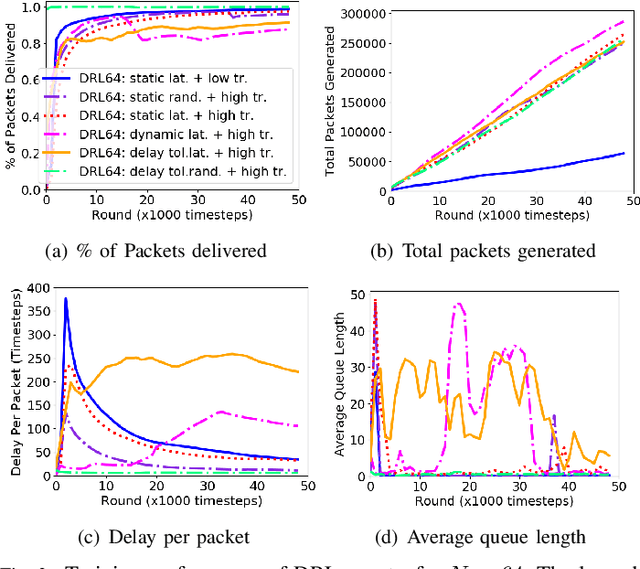
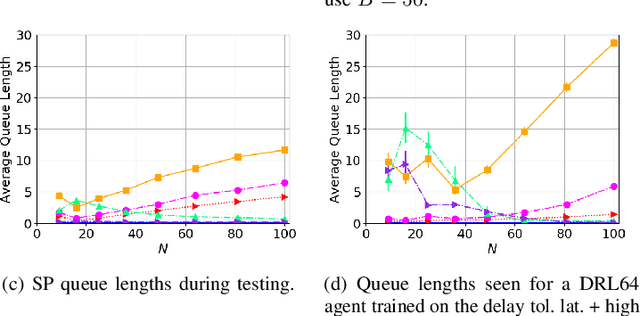
While routing in wireless networks has been studied extensively, existing protocols are typically designed for a specific set of network conditions and so cannot accommodate any drastic changes in those conditions. For instance, protocols designed for connected networks cannot be easily applied to disconnected networks. In this paper, we develop a distributed routing strategy based on deep reinforcement learning that generalizes to diverse traffic patterns, congestion levels, network connectivity, and link dynamics. We make the following key innovations in our design: (i) the use of relational features as inputs to the deep neural network approximating the decision space, which enables our algorithm to generalize to diverse network conditions, (ii) the use of packet-centric decisions to transform the routing problem into an episodic task by viewing packets, rather than wireless devices, as reinforcement learning agents, which provides a natural way to propagate and model rewards accurately during learning, and (iii) the use of extended-time actions to model the time spent by a packet waiting in a queue, which reduces the amount of training data needed and allows the learning algorithm to converge more quickly. We evaluate our routing algorithm using a packet-level simulator and show that the policy our algorithm learns during training is able to generalize to larger and more congested networks, different topologies, and diverse link dynamics. Our algorithm outperforms shortest path and backpressure routing with respect to packets delivered and delay per packet.