 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepDoseNet: A Deep Learning model for 3D Dose Prediction in Radiation Therapy
Oct 29, 2021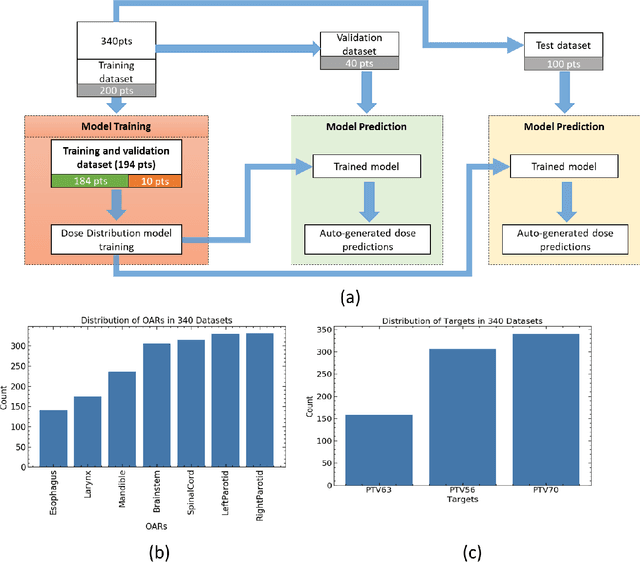
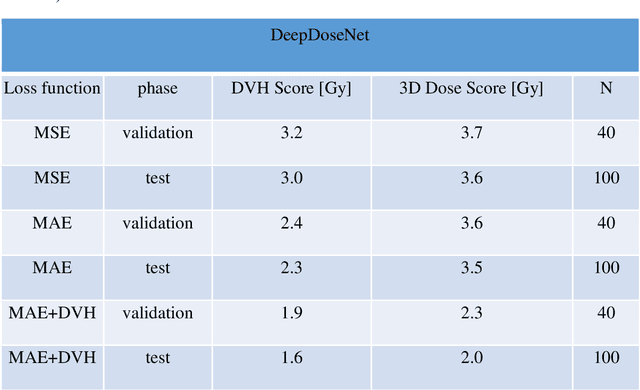
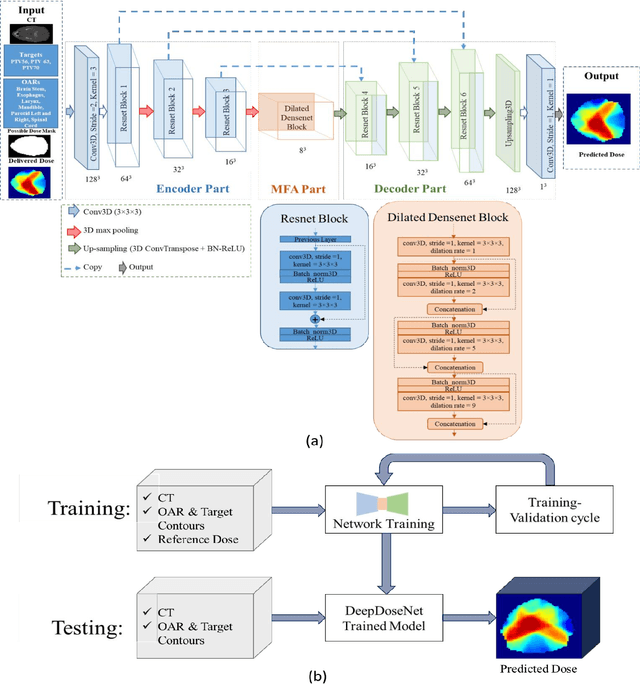
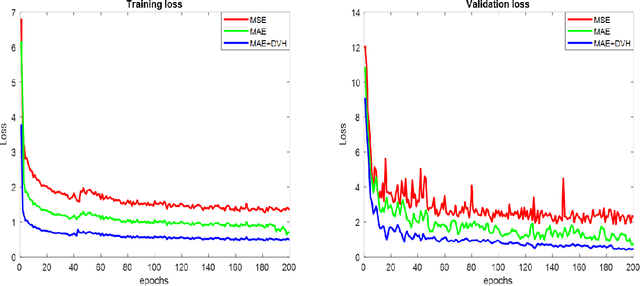
The DeepDoseNet 3D dose prediction model based on ResNet and Dilated DenseNet is proposed. The 340 head-and-neck datasets from the 2020 AAPM OpenKBP challenge were utilized, with 200 for training, 40 for validation, and 100 for testing. Structures include 56Gy, 63Gy, 70Gy PTVs, and brainstem, spinal cord, right parotid, left parotid, larynx, esophagus, and mandible OARs. Mean squared error (MSE) loss, mean absolute error (MAE) loss, and MAE plus dose-volume histogram (DVH) based loss functions were investigated. Each model's performance was compared using a 3D dose score, $\bar{S_{D}}$, (mean absolute difference between ground truth and predicted 3D dose distributions) and a DVH score, $\bar{S_{DVH}}$ (mean absolute difference between ground truth and predicted dose-volume metrics).Furthermore, DVH metrics Mean[Gy] and D0.1cc [Gy] for OARs and D99%, D95%, D1% for PTVs were computed. DeepDoseNet with the MAE plus DVH-based loss function had the best dose score performance of the OpenKBP entries. MAE+DVH model had the lowest prediction error (P<0.0001, Wilcoxon test) on validation and test datasets (validation: $\bar{S_{D}}$=2.3Gy, $\bar{S_{DVH}}$=1.9Gy; test: $\bar{S_{D}}$=2.0Gy, $\bar{S_{DVH}}$=1.6Gy) followed by the MAE model (validation: $\bar{S_{D}}$=3.6Gy, $\bar{S_{DVH}}$=2.4Gy; test: $\bar{S_{D}}$=3.5Gy, $\bar{S_{DVH}}$=2.3Gy). The MSE model had the highest prediction error (validation: $\bar{S_{D}}$=3.7Gy, $\bar{S_{DVH}}$=3.2Gy; test: $\bar{S_{D}}$=3.6Gy, $\bar{S_{DVH}}$=3.0Gy). No significant difference was found among models in terms of Mean [Gy], but the MAE+DVH model significantly outperformed the MAE and MSE models in terms of D0.1cc[Gy], particularly for mandible and parotids on both validation (P<0.01) and test (P<0.0001) datasets. MAE+DVH outperformed (P<0.0001) in terms of D99%, D95%, D1% for targets. MAE+DVH reduced $\bar{S_{D}}$ by ~60% and $\bar{S_{DVH}}$ by ~70%.
OARnet: Automated organs-at-risk delineation in Head and Neck CT images
Aug 31, 2021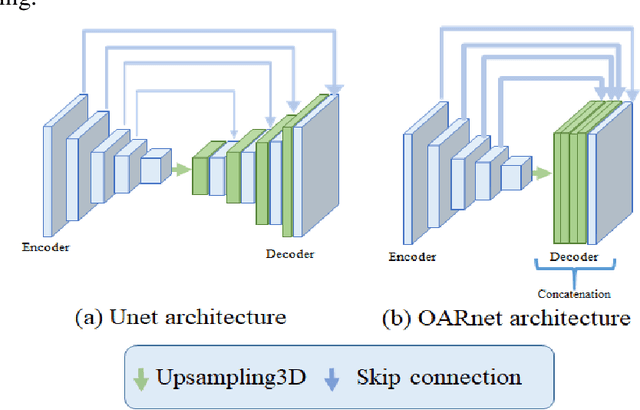
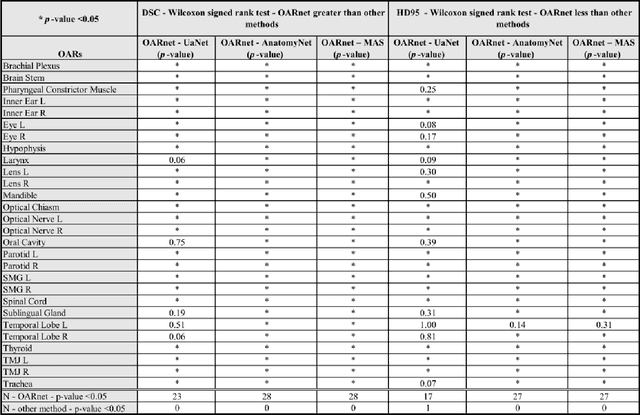
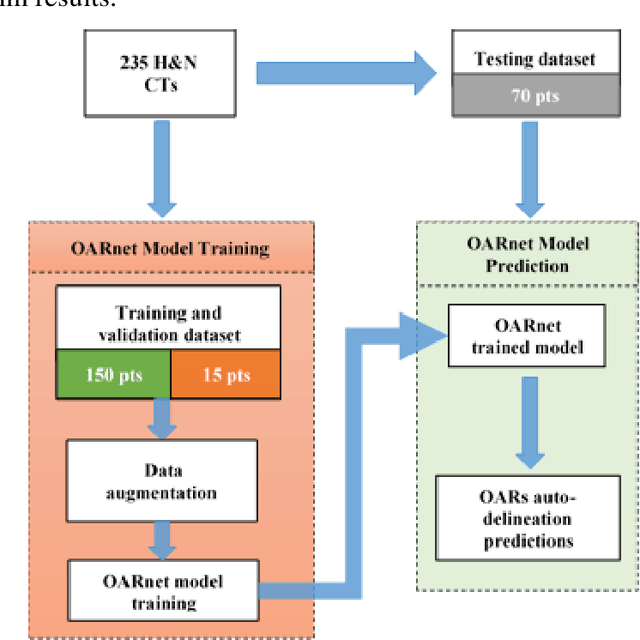
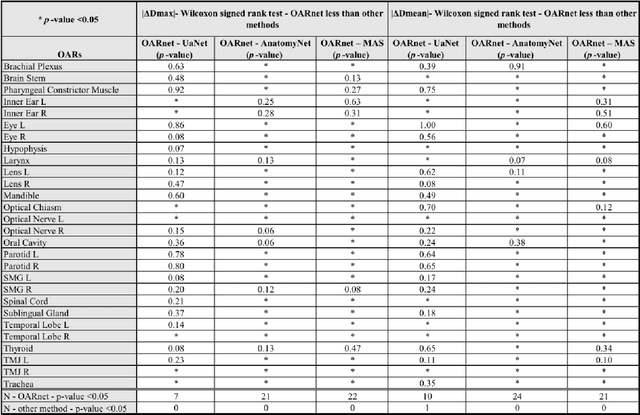
A 3D deep learning model (OARnet) is developed and used to delineate 28 H&N OARs on CT images. OARnet utilizes a densely connected network to detect the OAR bounding-box, then delineates the OAR within the box. It reuses information from any layer to subsequent layers and uses skip connections to combine information from different dense block levels to progressively improve delineation accuracy. Training uses up to 28 expert manual delineated (MD) OARs from 165 CTs. Dice similarity coefficient (DSC) and the 95th percentile Hausdorff distance (HD95) with respect to MD is assessed for 70 other CTs. Mean, maximum, and root-mean-square dose differences with respect to MD are assessed for 56 of the 70 CTs. OARnet is compared with UaNet, AnatomyNet, and Multi-Atlas Segmentation (MAS). Wilcoxon signed-rank tests using 95% confidence intervals are used to assess significance. Wilcoxon signed ranked tests show that, compared with UaNet, OARnet improves (p<0.05) the DSC (23/28 OARs) and HD95 (17/28). OARnet outperforms both AnatomyNet and MAS for DSC (28/28) and HD95 (27/28). Compared with UaNet, OARnet improves median DSC up to 0.05 and HD95 up to 1.5mm. Compared with AnatomyNet and MAS, OARnet improves median (DSC, HD95) by up to (0.08, 2.7mm) and (0.17, 6.3mm). Dosimetrically, OARnet outperforms UaNet (Dmax 7/28; Dmean 10/28), AnatomyNet (Dmax 21/28; Dmean 24/28), and MAS (Dmax 22/28; Dmean 21/28). The DenseNet architecture is optimized using a hybrid approach that performs OAR-specific bounding box detection followed by feature recognition. Compared with other auto-delineation methods, OARnet is better than or equal to UaNet for all but one geometric (Temporal Lobe L, HD95) and one dosimetric (Eye L, mean dose) endpoint for the 28 H&N OARs, and is better than or equal to both AnatomyNet and MAS for all OARs.