 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Dense Matching for Enhanced Gaussian Splatting Using AV1 Motion Vectors
May 14, 20263D Gaussian Splatting (3DGS) has emerged as a prominent framework for real-time, photorealistic scene reconstruction, offering significant speed-ups over Neural Radiance Fields (NeRF). However, the fidelity of 3DGS representations remains heavily dependent on the quality of the initial point cloud. While standard Structure-from-Motion (SfM) pipelines using COLMAP provide adequate initialisation, they often suffer from high computational costs and sparsity in textureless regions, which degrades subsequent reconstruction accuracy and convergence speed. In this work, we introduce an AV1-based feature detection and matching pipeline that significantly reduces SfM processing overhead. By leveraging motion vectors inherent to the AV1 video codec, we bypass computationally expensive exhaustive matching while maintaining geometric robustness. Our pipeline produces substantially denser point clouds, with up to eight times as many points as classical SfM. We demonstrate that this enhanced initialisation directly improves 3DGS performance, yielding an 9-point increase in VMAF and a 63% average reduction in training time required to reach baseline quality. The project page: https://sigmedia.tv/AV1-3DGS.github.io/
An Empirical Study of Reducing AV1 Decoder Complexity and Energy Consumption via Encoder Parameter Tuning
Oct 14, 2025The widespread adoption of advanced video codecs such as AV1 is often hindered by their high decoding complexity, posing a challenge for battery-constrained devices. While encoders can be configured to produce bitstreams that are decoder-friendly, estimating the decoding complexity and energy overhead for a given video is non-trivial. In this study, we systematically analyse the impact of disabling various coding tools and adjusting coding parameters in two AV1 encoders, libaom-av1 and SVT-AV1. Using system-level energy measurement tools like RAPL (Running Average Power Limit), Intel SoC Watch (integrated with VTune profiler), we quantify the resulting trade-offs between decoding complexity, energy consumption, and compression efficiency for decoding a bitstream. Our results demonstrate that specific encoder configurations can substantially reduce decoding complexity with minimal perceptual quality degradation. For libaom-av1, disabling CDEF, an in-loop filter gives us a mean reduction in decoding cycles by 10%. For SVT-AV1, using the in-built, fast-decode=2 preset achieves a more substantial 24% reduction in decoding cycles. These findings provide strategies for content providers to lower the energy footprint of AV1 video streaming.
LiteVPNet: A Lightweight Network for Video Encoding Control in Quality-Critical Applications
Oct 14, 2025In the last decade, video workflows in the cinema production ecosystem have presented new use cases for video streaming technology. These new workflows, e.g. in On-set Virtual Production, present the challenge of requiring precise quality control and energy efficiency. Existing approaches to transcoding often fall short of these requirements, either due to a lack of quality control or computational overhead. To fill this gap, we present a lightweight neural network (LiteVPNet) for accurately predicting Quantisation Parameters for NVENC AV1 encoders that achieve a specified VMAF score. We use low-complexity features, including bitstream characteristics, video complexity measures, and CLIP-based semantic embeddings. Our results demonstrate that LiteVPNet achieves mean VMAF errors below 1.2 points across a wide range of quality targets. Notably, LiteVPNet achieves VMAF errors within 2 points for over 87% of our test corpus, c.f. approx 61% with state-of-the-art methods. LiteVPNet's performance across various quality regions highlights its applicability for enhancing high-value content transport and streaming for more energy-efficient, high-quality media experiences.
Demystifying the use of Compression in Virtual Production
Nov 01, 2024Virtual Production (VP) technologies have continued to improve the flexibility of on-set filming and enhance the live concert experience. The core technology of VP relies on high-resolution, high-brightness LED panels to playback/render video content. There are a number of technical challenges to effective deployment e.g. image tile synchronisation across the panels, cross panel colour balancing and compensating for colour fluctuations due to changes in camera angles. Given the complexity and potential quality degradation, the industry prefers "pristine" or lossless compressed source material for displays, which requires significant storage and bandwidth. Modern lossy compression standards like AV1 or H.265 could maintain the same quality at significantly lower bitrates and resource demands. There is yet no agreed methodology for assessing the impact of these standards on quality when the VP scene is recorded in-camera. We present a methodology to assess this impact by comparing lossless and lossy compressed footage displayed through VP screens and recorded in-camera. We assess the quality impact of HAP/NotchLC/Daniel2 and AV1/HEVC/H.264 compression bitrates from 2 Mb/s to 2000 Mb/s with various GOP sizes. Several perceptual quality metrics are then used to automatically evaluate in-camera picture quality, referencing the original uncompressed source content through the LED wall. Our results show that we can achieve the same quality with hybrid codecs as with intermediate encoders at orders of magnitude less bitrate and storage requirements.
Predicting total time to compress a video corpus using online inference systems
Oct 23, 2024Predicting the computational cost of compressing/transcoding clips in a video corpus is important for resource management of cloud services and VOD (Video On Demand) providers. Currently, customers of cloud video services are unaware of the cost of transcoding their files until the task is completed. Previous work concentrated on predicting perclip compression time, and thus estimating the cost of video compression. In this work, we propose new Machine Learning (ML) systems which predict cost for the entire corpus instead. This is a more appropriate goal since users are not interested in per-clip cost but instead the cost for the whole corpus. In this work, we evaluate our systems with respect to two video codecs (x264, x265) and a novel high-quality video corpus. We find that the accuracy of aggregate time prediction for a video corpus more than two times better than using per-clip predictions. Furthermore, we present an online inference framework in which we update the ML models as files are processed. A consideration of video compute overhead and appropriate choice of ML predictor for each fraction of corpus completed yields a prediction error of less than 5%. This is approximately two times better than previous work which proposed generalised predictors.
Unravelling the Power of Single-Pass Look-Ahead in Modern Codecs for Optimized Transcoding Deployment
Apr 08, 2024
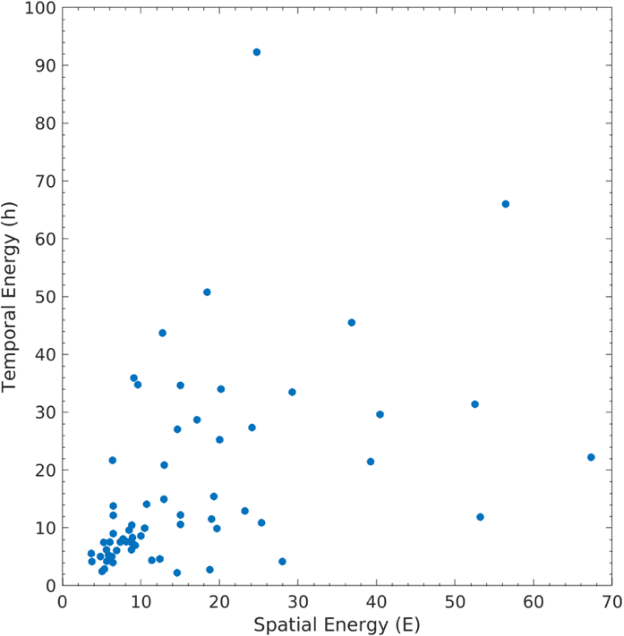
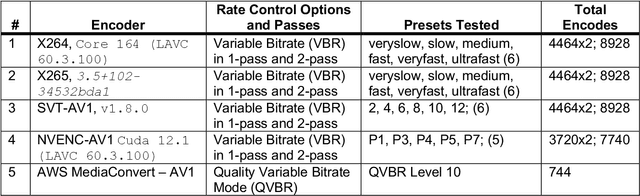
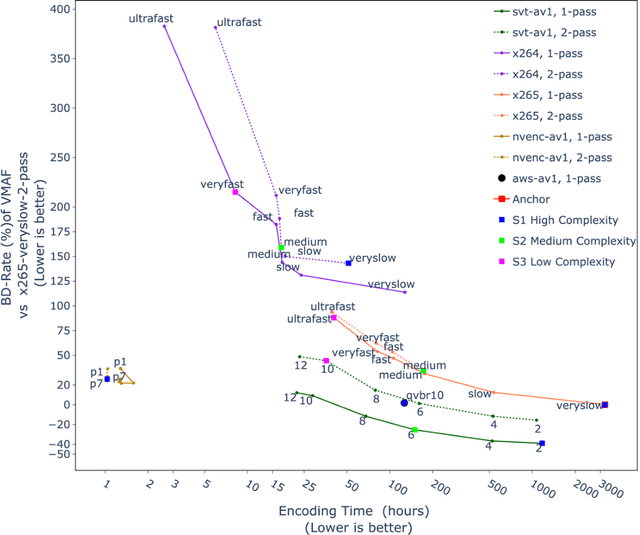
Modern video encoders have evolved into sophisticated pieces of software in which various coding tools interact with each other. In the past, singlepass encoding was not considered for Video-On-Demand (VOD) use cases. In this work, we evaluate production-ready encoders for H.264 (x264), H.265 (HEVC), AV1 (SVT-AV1) along with direct comparisons to the latest AV1 encoder inside NVIDIA GPUs (40 series), and AWS Mediaconvert's AV1 implementation. Our experimental results demonstrate single pass encoding inside modern encoder implementations can give us very good quality at a reasonable compute cost. The results are presented as three different scenarios targeting High, Medium, and Low complexity accounting quality/bitrate/compute load. Finally, a set of recommendations is presented for end-users to help decide which encoder/preset combination might be more suited to their use case.