 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting Dependency of Unlabeled Databases
Nov 10, 2023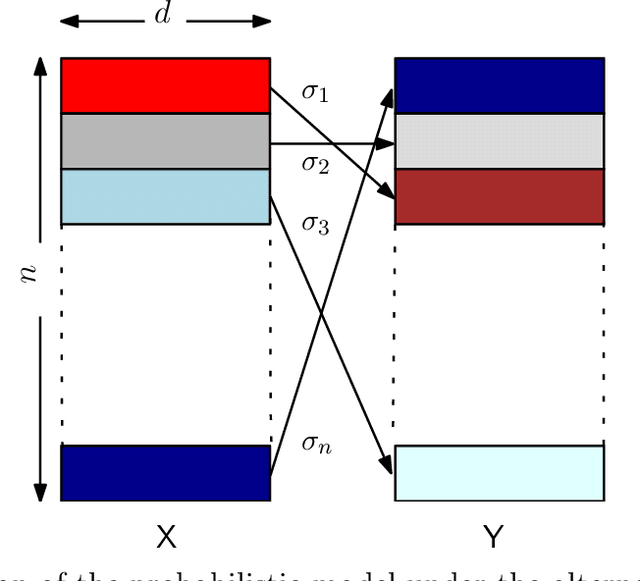
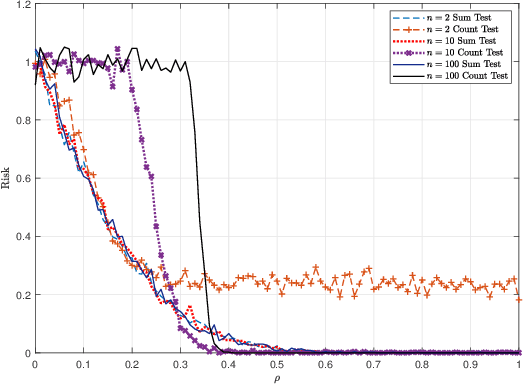
In this paper, we investigate the problem of deciding whether two random databases $\mathsf{X}\in\mathcal{X}^{n\times d}$ and $\mathsf{Y}\in\mathcal{Y}^{n\times d}$ are statistically dependent or not. This is formulated as a hypothesis testing problem, where under the null hypothesis, these two databases are statistically independent, while under the alternative, there exists an unknown row permutation $\sigma$, such that $\mathsf{X}$ and $\mathsf{Y}^\sigma$, a permuted version of $\mathsf{Y}$, are statistically dependent with some known joint distribution, but have the same marginal distributions as the null. We characterize the thresholds at which optimal testing is information-theoretically impossible and possible, as a function of $n$, $d$, and some spectral properties of the generative distributions of the datasets. For example, we prove that if a certain function of the eigenvalues of the likelihood function and $d$, is below a certain threshold, as $d\to\infty$, then weak detection (performing slightly better than random guessing) is statistically impossible, no matter what the value of $n$ is. This mimics the performance of an efficient test that thresholds a centered version of the log-likelihood function of the observed matrices. We also analyze the case where $d$ is fixed, for which we derive strong (vanishing error) and weak detection lower and upper bounds.