 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Performance Interference Among Network Slices in 5G/6G Systems
Dec 02, 2024



Recent studies showed that network slices (NSs), which are logical networks supported by shared physical networks, can experience service interference due to sharing of physical and virtual resources. Thus, from the perspective of providing end-to-end (E2E) service quality assurance in 5G/6G systems, it is crucial to discover possible service interference among the NSs in a timely manner and isolate the potential issues before they can lead to violations of service quality agreements. We study the problem of detecting service interference among NSs in 5G/6G systems, only using E2E key performance indicator measurements, and propose a new algorithm. Our numerical studies demonstrate that, even when the service interference among NSs is weak to moderate, provided that a reasonable number of measurements are available, the proposed algorithm can correctly identify most of shared resources that can cause service interference among the NSs that utilize the shared resources.
Federated Learning with Server Learning: Enhancing Performance for Non-IID Data
Oct 06, 2022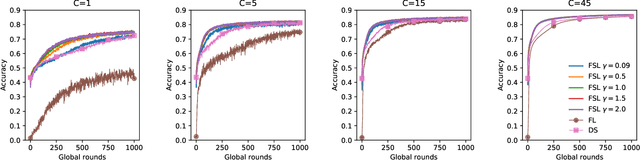
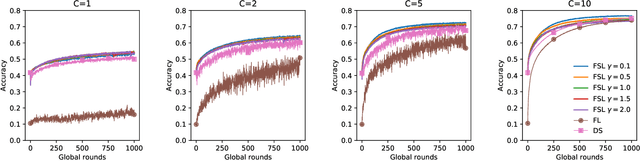
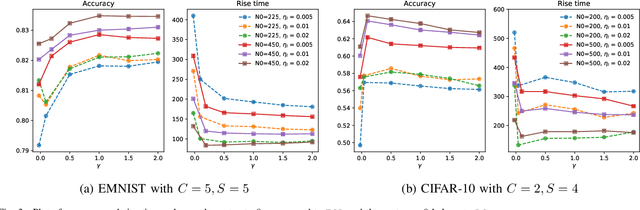
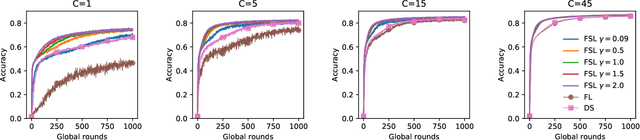
Federated learning (FL) has become a popular means for distributed learning at clients using local data samples. However, recent studies have shown that FL may experience slow learning and poor performance when client data are not independent and identically distributed (IID). This paper proposes a new federated learning algorithm, where the central server has access to a small dataset, learns from it, and fuses the knowledge into the global model through the federated learning process. This new approach, referred to as Federated learning with Server Learning or FSL, is complementary to and can be combined with other FL learning algorithms. We prove the convergence of FSL and demonstrate its benefits through analysis and simulations. We also reveal an inherent trade-off: when the current model is far from any local minimizer, server learning can significantly improve and accelerate FL. On the other hand, when the model is close to a local minimizer, server learning could potentially affect the convergence neighborhood of FL due to variances in the estimated gradient used by the server. We show via simulations that such trade-off can be tuned easily to provide significant benefits, even when the server dataset is very small.