 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI've got the "Answer"! Interpretation of LLMs Hidden States in Question Answering
Jun 04, 2024



Interpretability and explainability of AI are becoming increasingly important in light of the rapid development of large language models (LLMs). This paper investigates the interpretation of LLMs in the context of the knowledge-based question answering. The main hypothesis of the study is that correct and incorrect model behavior can be distinguished at the level of hidden states. The quantized models LLaMA-2-7B-Chat, Mistral-7B, Vicuna-7B and the MuSeRC question-answering dataset are used to test this hypothesis. The results of the analysis support the proposed hypothesis. We also identify the layers which have a negative effect on the model's behavior. As a prospect of practical application of the hypothesis, we propose to train such "weak" layers additionally in order to improve the quality of the task solution.
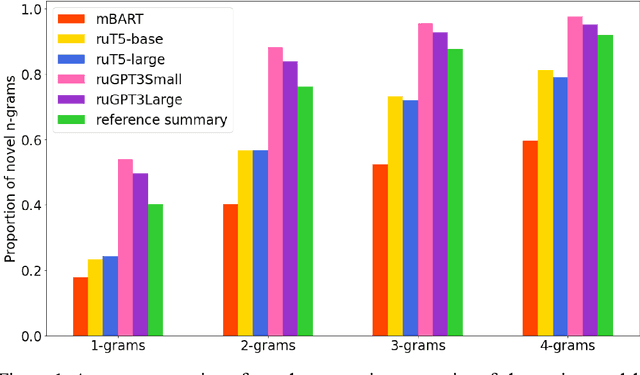
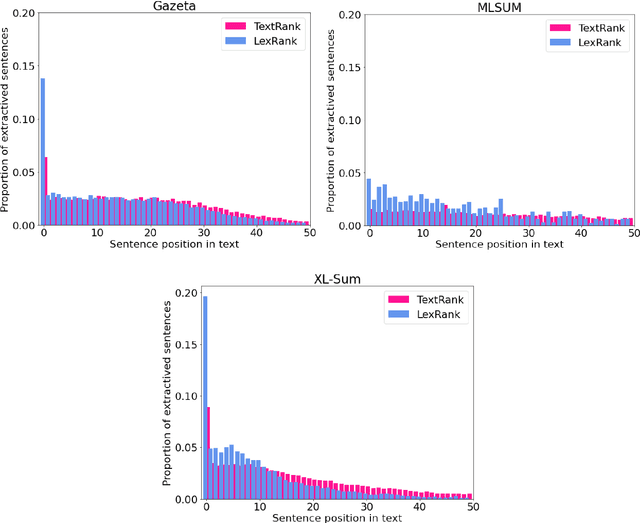
Automatic Summarization of Russian Texts: Comparison of Extractive and Abstractive Methods
Jun 18, 2022

The development of large and super-large language models, such as GPT-3, T5, Switch Transformer, ERNIE, etc., has significantly improved the performance of text generation. One of the important research directions in this area is the generation of texts with arguments. The solution of this problem can be used in business meetings, political debates, dialogue systems, for preparation of student essays. One of the main domains for these applications is the economic sphere. The key problem of the argument text generation for the Russian language is the lack of annotated argumentation corpora. In this paper, we use translated versions of the Argumentative Microtext, Persuasive Essays and UKP Sentential corpora to fine-tune RuBERT model. Further, this model is used to annotate the corpus of economic news by argumentation. Then the annotated corpus is employed to fine-tune the ruGPT-3 model, which generates argument texts. The results show that this approach improves the accuracy of the argument generation by more than 20 percentage points (63.2% vs. 42.5%) compared to the original ruGPT-3 model.
Traditional Machine Learning and Deep Learning Models for Argumentation Mining in Russian Texts
Jun 28, 2021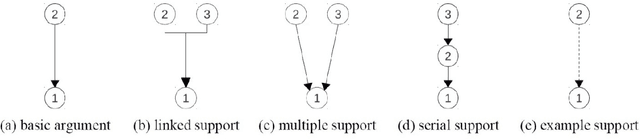
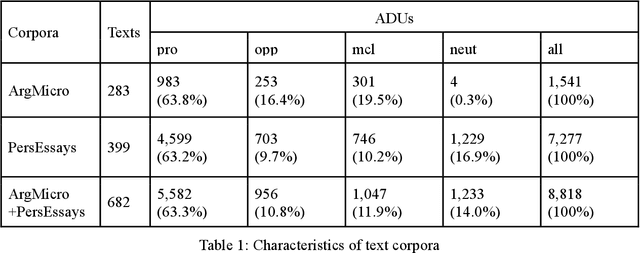
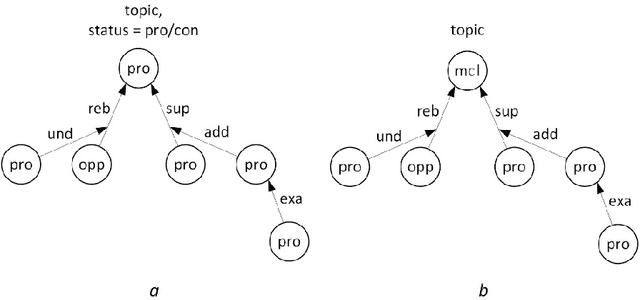
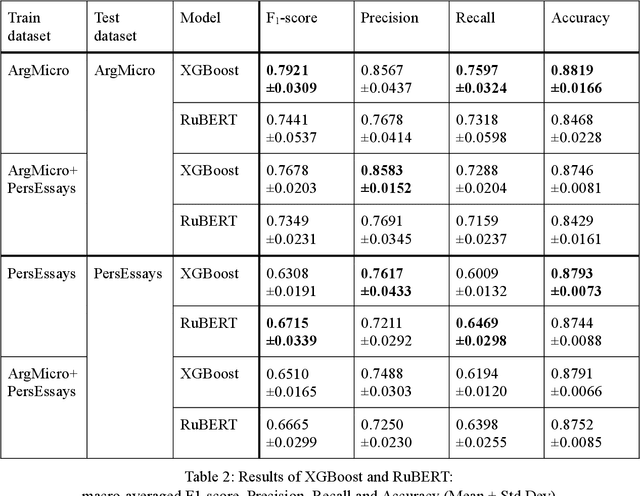
Argumentation mining is a field of computational linguistics that is devoted to extracting from texts and classifying arguments and relations between them, as well as constructing an argumentative structure. A significant obstacle to research in this area for the Russian language is the lack of annotated Russian-language text corpora. This article explores the possibility of improving the quality of argumentation mining using the extension of the Russian-language version of the Argumentative Microtext Corpus (ArgMicro) based on the machine translation of the Persuasive Essays Corpus (PersEssays). To make it possible to use these two corpora combined, we propose a Joint Argument Annotation Scheme based on the schemes used in ArgMicro and PersEssays. We solve the problem of classifying argumentative discourse units (ADUs) into two classes - "pro" ("for") and "opp" ("against") using traditional machine learning techniques (SVM, Bagging and XGBoost) and a deep neural network (BERT model). An ensemble of XGBoost and BERT models was proposed, which showed the highest performance of ADUs classification for both corpora.