 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraditional Machine Learning and Deep Learning Models for Argumentation Mining in Russian Texts
Paper and Code
Jun 28, 2021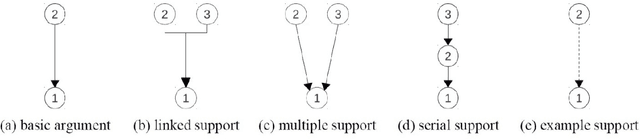
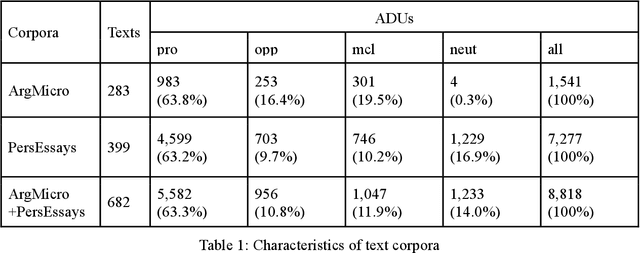
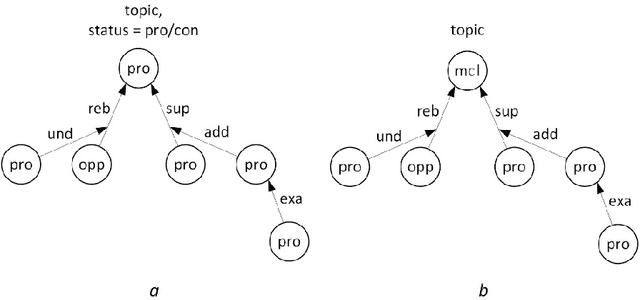
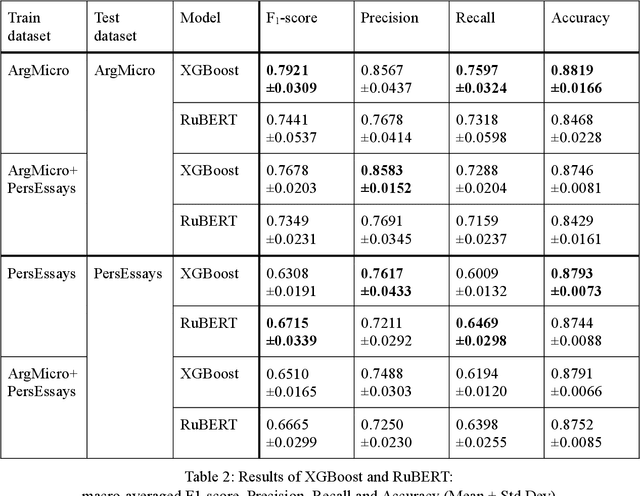
Argumentation mining is a field of computational linguistics that is devoted to extracting from texts and classifying arguments and relations between them, as well as constructing an argumentative structure. A significant obstacle to research in this area for the Russian language is the lack of annotated Russian-language text corpora. This article explores the possibility of improving the quality of argumentation mining using the extension of the Russian-language version of the Argumentative Microtext Corpus (ArgMicro) based on the machine translation of the Persuasive Essays Corpus (PersEssays). To make it possible to use these two corpora combined, we propose a Joint Argument Annotation Scheme based on the schemes used in ArgMicro and PersEssays. We solve the problem of classifying argumentative discourse units (ADUs) into two classes - "pro" ("for") and "opp" ("against") using traditional machine learning techniques (SVM, Bagging and XGBoost) and a deep neural network (BERT model). An ensemble of XGBoost and BERT models was proposed, which showed the highest performance of ADUs classification for both corpora.