 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlmawave-SLU: A new dataset for SLU in Italian
Jul 17, 2019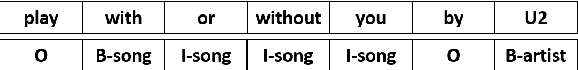

The widespread use of conversational and question answering systems made it necessary to improve the performances of speaker intent detection and understanding of related semantic slots, i.e., Spoken Language Understanding (SLU). Often, these tasks are approached with supervised learning methods, which needs considerable labeled datasets. This paper presents the first Italian dataset for SLU. It is derived through a semi-automatic procedure and is used as a benchmark of various open source and commercial systems.
Multi-lingual Intent Detection and Slot Filling in a Joint BERT-based Model
Jul 05, 2019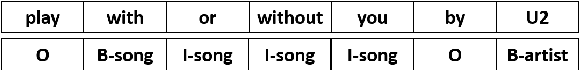

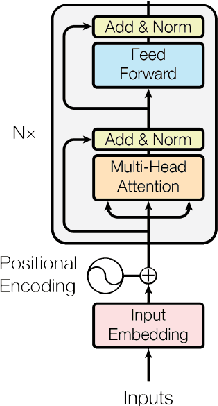

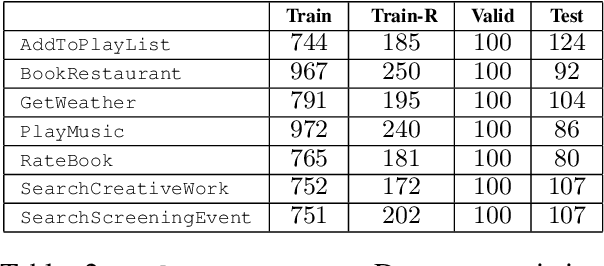
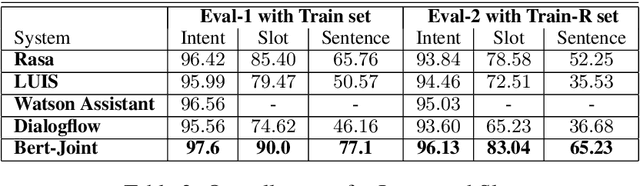
Intent Detection and Slot Filling are two pillar tasks in Spoken Natural Language Understanding. Common approaches adopt joint Deep Learning architectures in attention-based recurrent frameworks. In this work, we aim at exploiting the success of "recurrence-less" models for these tasks. We introduce Bert-Joint, i.e., a multi-lingual joint text classification and sequence labeling framework. The experimental evaluation over two well-known English benchmarks demonstrates the strong performances that can be obtained with this model, even when few annotated data is available. Moreover, we annotated a new dataset for the Italian language, and we observed similar performances without the need for changing the model.