Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlmawave-SLU: A new dataset for SLU in Italian
Paper and Code
Jul 17, 2019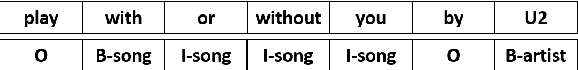

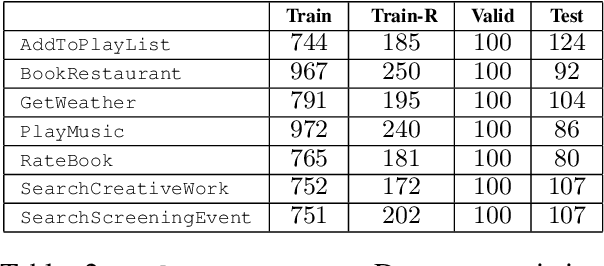
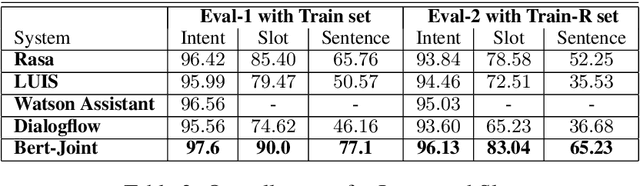
The widespread use of conversational and question answering systems made it necessary to improve the performances of speaker intent detection and understanding of related semantic slots, i.e., Spoken Language Understanding (SLU). Often, these tasks are approached with supervised learning methods, which needs considerable labeled datasets. This paper presents the first Italian dataset for SLU. It is derived through a semi-automatic procedure and is used as a benchmark of various open source and commercial systems.
View paper on