 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Perspective on the Dynamics of Deep Transformers
Jan 30, 2025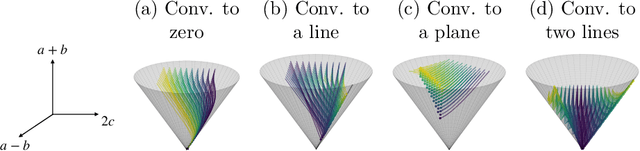
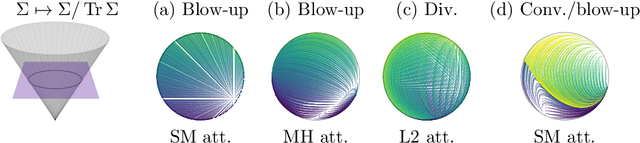
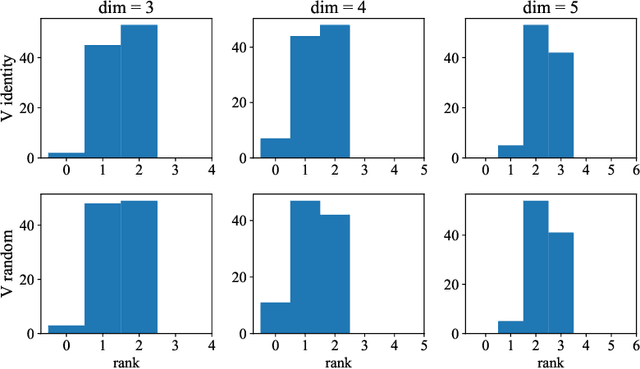
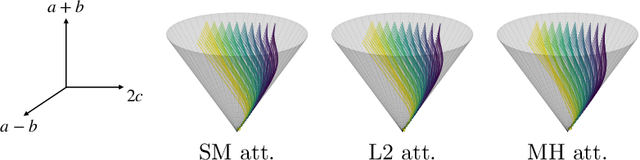
Transformers, which are state-of-the-art in most machine learning tasks, represent the data as sequences of vectors called tokens. This representation is then exploited by the attention function, which learns dependencies between tokens and is key to the success of Transformers. However, the iterative application of attention across layers induces complex dynamics that remain to be fully understood. To analyze these dynamics, we identify each input sequence with a probability measure and model its evolution as a Vlasov equation called Transformer PDE, whose velocity field is non-linear in the probability measure. Our first set of contributions focuses on compactly supported initial data. We show the Transformer PDE is well-posed and is the mean-field limit of an interacting particle system, thus generalizing and extending previous analysis to several variants of self-attention: multi-head attention, L2 attention, Sinkhorn attention, Sigmoid attention, and masked attention--leveraging a conditional Wasserstein framework. In a second set of contributions, we are the first to study non-compactly supported initial conditions, by focusing on Gaussian initial data. Again for different types of attention, we show that the Transformer PDE preserves the space of Gaussian measures, which allows us to analyze the Gaussian case theoretically and numerically to identify typical behaviors. This Gaussian analysis captures the evolution of data anisotropy through a deep Transformer. In particular, we highlight a clustering phenomenon that parallels previous results in the non-normalized discrete case.
Understanding the Regularity of Self-Attention with Optimal Transport
Dec 22, 2023
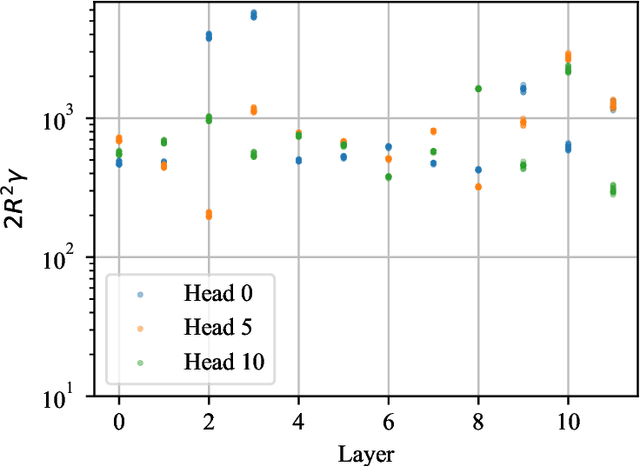
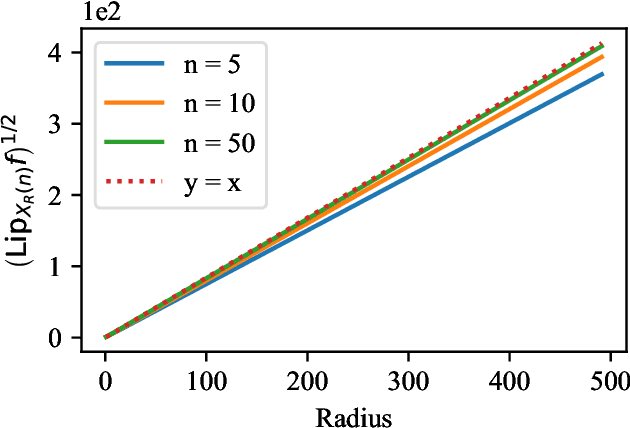
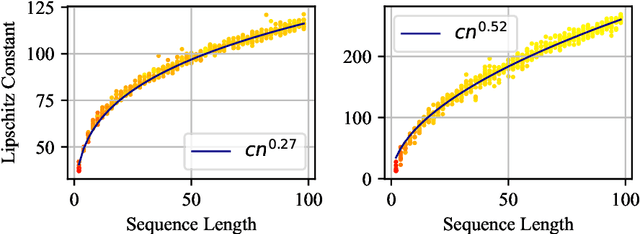
Transformers and their multi-head attention mechanism have completely changed the machine learning landscape in just a few years, by outperforming state-of-art models in a wide range of domains. Still, little is known about their robustness from a theoretical perspective. We tackle this problem by studying the local Lipschitz constant of self-attention, that provides an attack-agnostic way of measuring the robustness of a neural network. We adopt a measure-theoretic framework, by viewing inputs as probability measures equipped with the Wasserstein distance. This allows us to generalize attention to inputs of infinite length, and to derive an upper bound and a lower bound on the Lipschitz constant of self-attention on compact sets. The lower bound significantly improves prior results, and grows more than exponentially with the radius of the compact set, which rules out the possibility of obtaining robustness guarantees without any additional constraint on the input space. Our results also point out that measures with a high local Lipschitz constant are typically made of a few diracs, with a very unbalanced distribution of mass. Finally, we analyze the stability of self-attention under perturbations that change the number of tokens, which appears to be a natural question in the measure-theoretic framework. In particular, we show that for some inputs, attacks that duplicate tokens before perturbing them are more efficient than attacks that simply move tokens. We call this phenomenon mass splitting.