 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-multi-SNE: Semi-Supervised Classification and Visualisation of Multi-View Data
Nov 05, 2021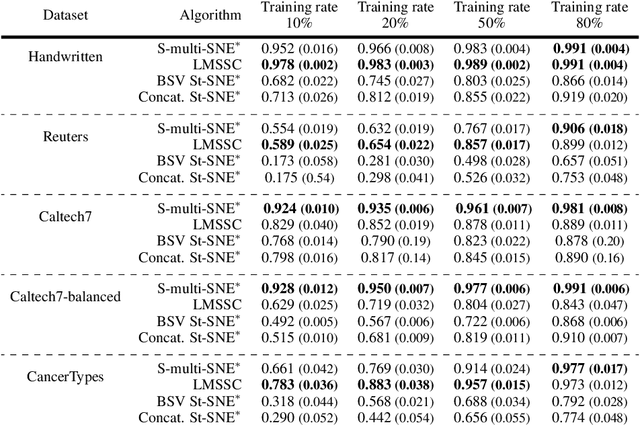
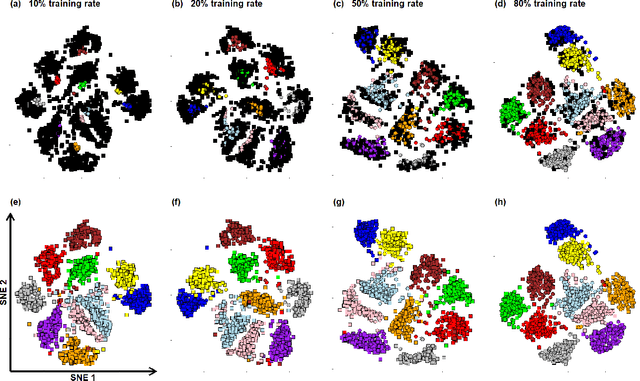
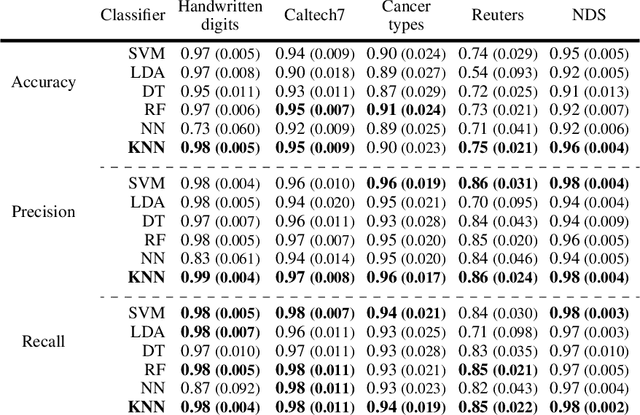
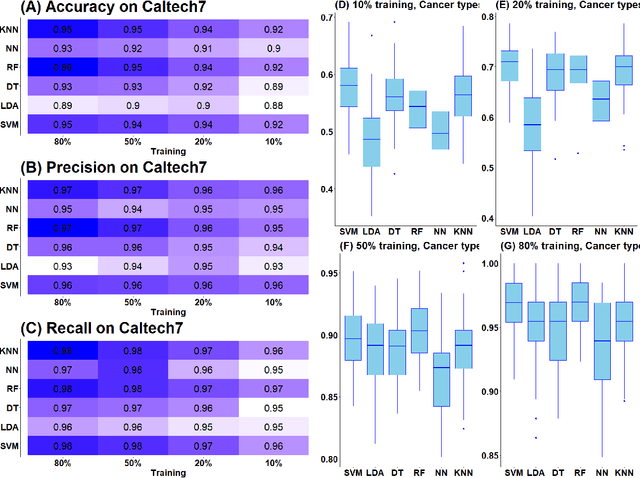
An increasing number of multi-view data are being published by studies in several fields. This type of data corresponds to multiple data-views, each representing a different aspect of the same set of samples. We have recently proposed multi-SNE, an extension of t-SNE, that produces a single visualisation of multi-view data. The multi-SNE approach provides low-dimensional embeddings of the samples, produced by being updated iteratively through the different data-views. Here, we further extend multi-SNE to a semi-supervised approach, that classifies unlabelled samples by regarding the labelling information as an extra data-view. We look deeper into the performance, limitations and strengths of multi-SNE and its extension, S-multi-SNE, by applying the two methods on various multi-view datasets with different challenges. We show that by including the labelling information, the projection of the samples improves drastically and it is accompanied by a strong classification performance.
Multi-view Data Visualisation via Manifold Learning
Jan 17, 2021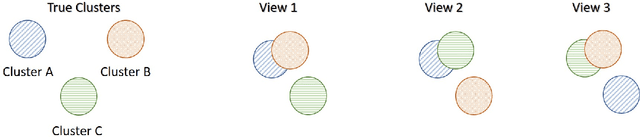
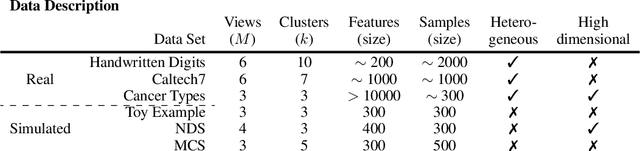

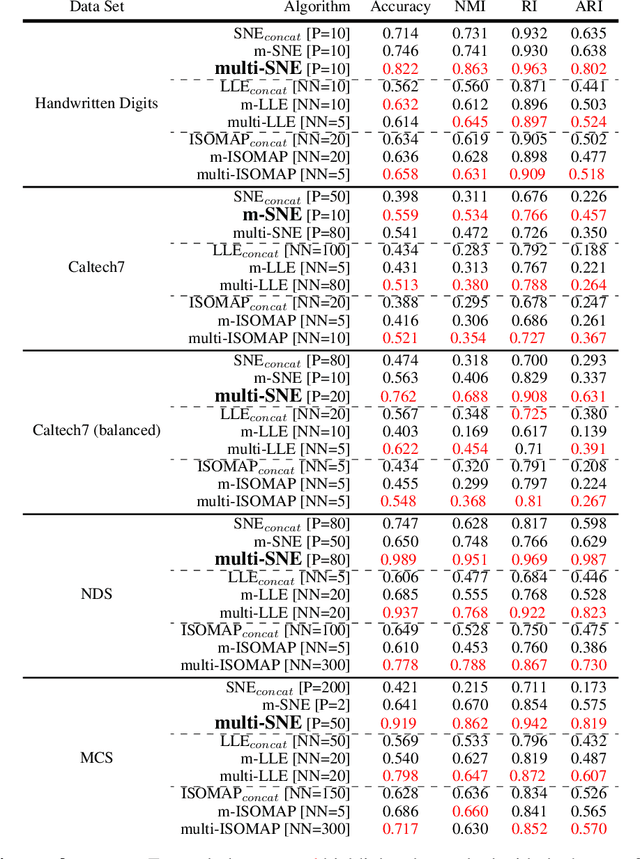
Manifold learning approaches, such as Stochastic Neighbour Embedding (SNE), Locally Linear Embedding (LLE) and Isometric Feature Mapping (ISOMAP) have been proposed for performing non-linear dimensionality reduction. These methods aim to produce two or three latent embeddings, in order to visualise the data in intelligible representations. This manuscript proposes extensions of Student's t-distributed SNE (t-SNE), LLE and ISOMAP, to allow for dimensionality reduction and subsequent visualisation of multi-view data. Nowadays, it is very common to have multiple data-views on the same samples. Each data-view contains a set of features describing different aspects of the samples. For example, in biomedical studies it is possible to generate multiple OMICS data sets for the same individuals, such as transcriptomics, genomics, epigenomics, enabling better understanding of the relationships between the different biological processes. Through the analysis of real and simulated datasets, the visualisation performance of the proposed methods is illustrated. Data visualisations have been often utilised for identifying any potential clusters in the data sets. We show that by incorporating the low-dimensional embeddings obtained via the multi-view manifold learning approaches into the K-means algorithm, clusters of the samples are accurately identified. Our proposed multi-SNE method outperforms the corresponding multi-ISOMAP and multi-LLE proposed methods. Interestingly, multi-SNE is found to have comparable performance with methods proposed in the literature for performing multi-view clustering.