 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexicon and Attention based Handwritten Text Recognition System
Sep 11, 2022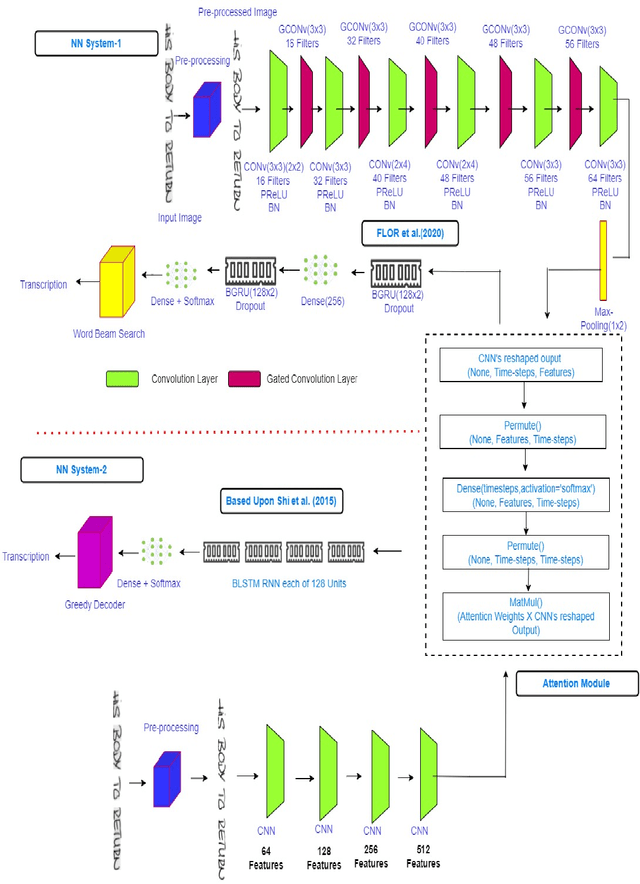

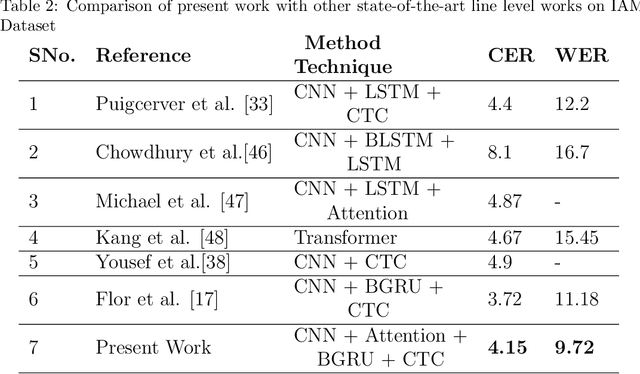
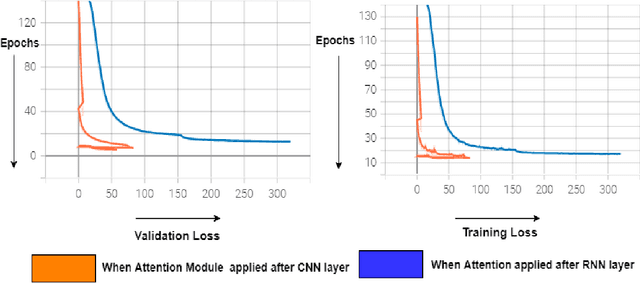
The handwritten text recognition problem is widely studied by the researchers of computer vision community due to its scope of improvement and applicability to daily lives, It is a sub-domain of pattern recognition. Due to advancement of computational power of computers since last few decades neural networks based systems heavily contributed towards providing the state-of-the-art handwritten text recognizers. In the same direction, we have taken two state-of-the art neural networks systems and merged the attention mechanism with it. The attention technique has been widely used in the domain of neural machine translations and automatic speech recognition and now is being implemented in text recognition domain. In this study, we are able to achieve 4.15% character error rate and 9.72% word error rate on IAM dataset, 7.07% character error rate and 16.14% word error rate on GW dataset after merging the attention and word beam search decoder with existing Flor et al. architecture. To analyse further, we have also used system similar to Shi et al. neural network system with greedy decoder and observed 23.27% improvement in character error rate from the base model.
A Lexicon and Depth-wise Separable Convolution Based Handwritten Text Recognition System
Jul 11, 2022
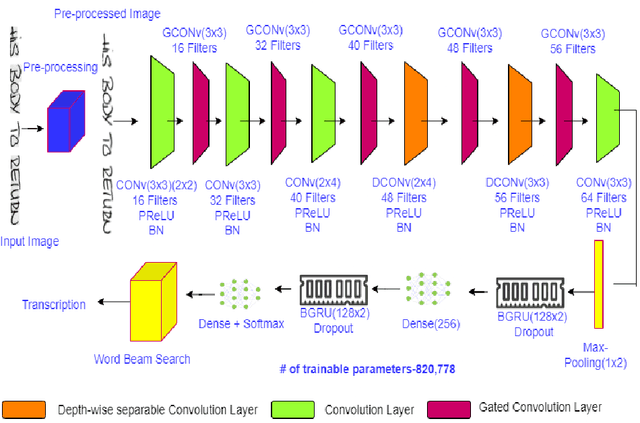
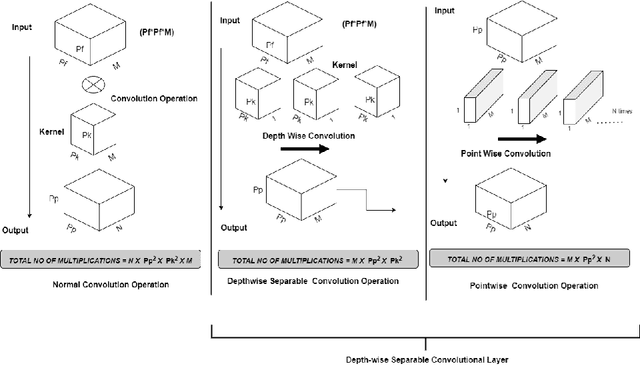

Cursive handwritten text recognition is a challenging research problem in the domain of pattern recognition. The current state-of-the-art approaches include models based on convolutional recurrent neural networks and multi-dimensional long short-term memory recurrent neural networks techniques. These methods are highly computationally extensive as well model is complex at design level. In recent studies, combination of convolutional neural network and gated convolutional neural networks based models demonstrated less number of parameters in comparison to convolutional recurrent neural networks based models. In the direction to reduced the total number of parameters to be trained, in this work, we have used depthwise convolution in place of standard convolutions with a combination of gated-convolutional neural network and bidirectional gated recurrent unit to reduce the total number of parameters to be trained. Additionally, we have also included a lexicon based word beam search decoder at testing step. It also helps in improving the the overall accuracy of the model. We have obtained 3.84% character error rate and 9.40% word error rate on IAM dataset; 4.88% character error rate and 14.56% word error rate in George Washington dataset, respectively.