 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Performance of English-Tamil Statistical Machine Translation System using Source-Side Pre-Processing
Sep 29, 2014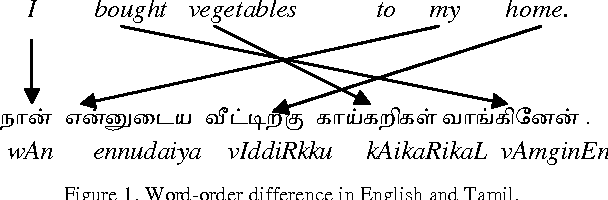
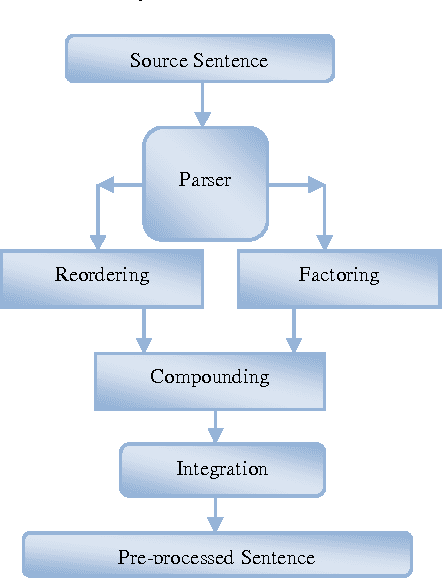
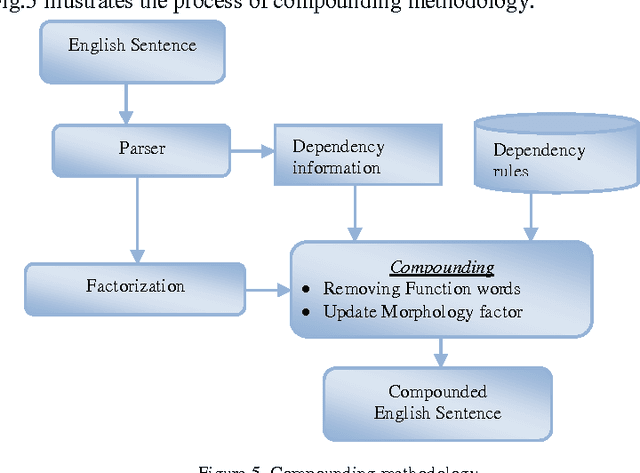

Machine Translation is one of the major oldest and the most active research area in Natural Language Processing. Currently, Statistical Machine Translation (SMT) dominates the Machine Translation research. Statistical Machine Translation is an approach to Machine Translation which uses models to learn translation patterns directly from data, and generalize them to translate a new unseen text. The SMT approach is largely language independent, i.e. the models can be applied to any language pair. Statistical Machine Translation (SMT) attempts to generate translations using statistical methods based on bilingual text corpora. Where such corpora are available, excellent results can be attained translating similar texts, but such corpora are still not available for many language pairs. Statistical Machine Translation systems, in general, have difficulty in handling the morphology on the source or the target side especially for morphologically rich languages. Errors in morphology or syntax in the target language can have severe consequences on meaning of the sentence. They change the grammatical function of words or the understanding of the sentence through the incorrect tense information in verb. Baseline SMT also known as Phrase Based Statistical Machine Translation (PBSMT) system does not use any linguistic information and it only operates on surface word form. Recent researches shown that adding linguistic information helps to improve the accuracy of the translation with less amount of bilingual corpora. Adding linguistic information can be done using the Factored Statistical Machine Translation system through pre-processing steps. This paper investigates about how English side pre-processing is used to improve the accuracy of English-Tamil SMT system.