 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the significance of using perceptually relevant image decolorization method for scene classification
Dec 29, 2017A color image contains luminance and chrominance components representing the intensity and color information respectively. The objective of the work presented in this paper is to show the significance of incorporating the chrominance information for the task of scene classification. An improved color-to-grayscale image conversion algorithm by effectively incorporating the chrominance information is proposed using color-to-gay structure similarity index (C2G-SSIM) and singular value decomposition (SVD) to improve the perceptual quality of the converted grayscale images. The experimental result analysis based on the image quality assessment for image decolorization called C2G-SSIM and success rate (Cadik and COLOR250 datasets) shows that the proposed image decolorization technique performs better than 8 existing benchmark algorithms for image decolorization. In the second part of the paper, the effectiveness of incorporating the chrominance component in scene classification task is demonstrated using the deep belief network (DBN) based image classification system developed using dense scale invariant feature transform (SIFT) as features. The levels of chrominance information incorporated by the proposed image decolorization technique is confirmed by the improvement in the overall scene classification accuracy . Also, the overall scene classification performance is improved by the combination of models obtained using the proposed and the conventional decolorization methods.
* This article is accepted in SPIE J.of Electronic Imaging with title: Significance of perceptually relevant image decolorization for scene classification
A new TAG Formalism for Tamil and Parser Analytics
Apr 05, 2016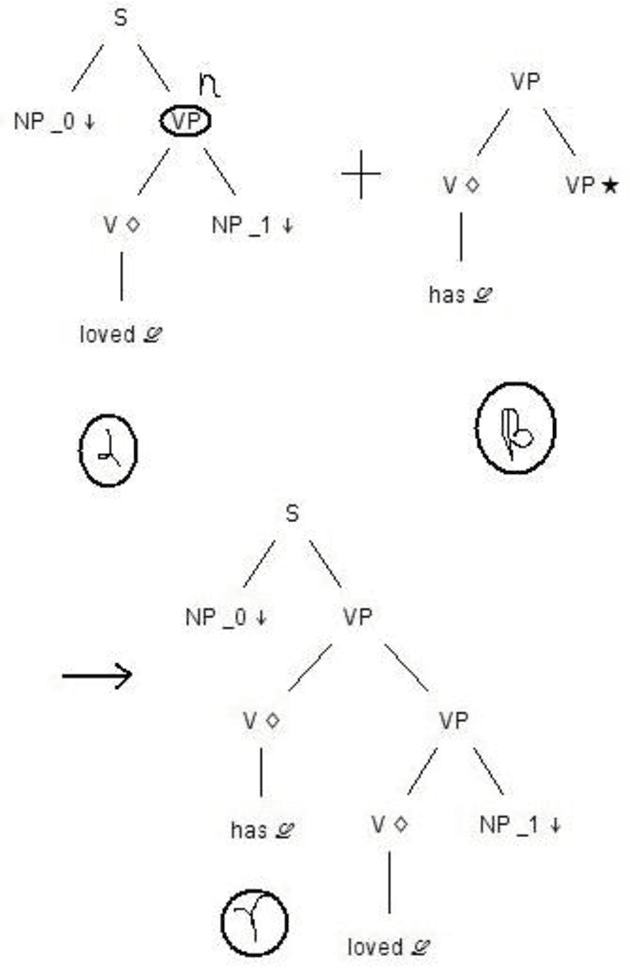
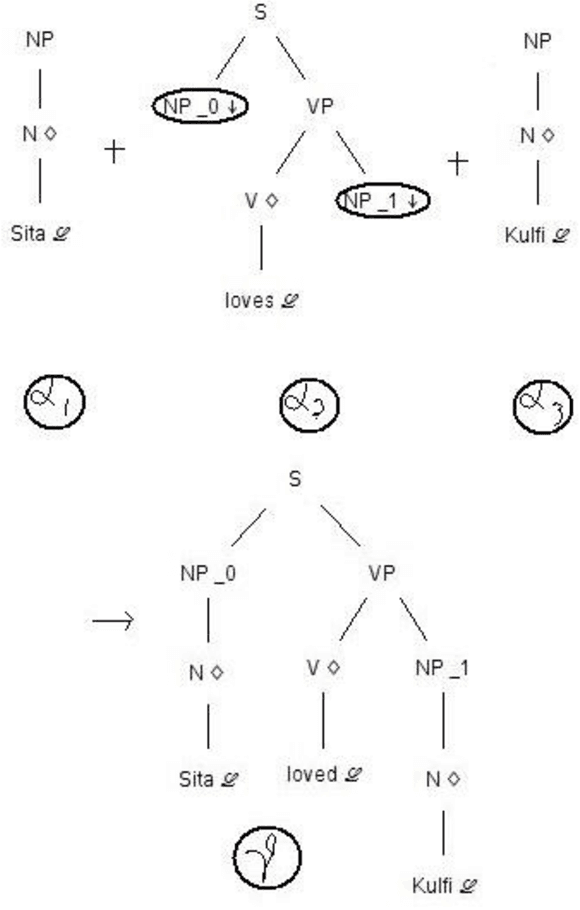

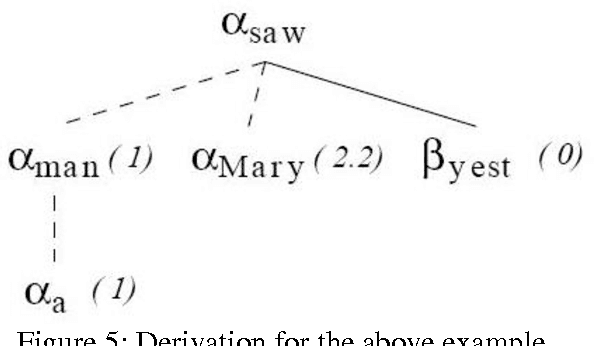
Tree adjoining grammar (TAG) is specifically suited for morph rich and agglutinated languages like Tamil due to its psycho linguistic features and parse time dependency and morph resolution. Though TAG and LTAG formalisms have been known for about 3 decades, efforts on designing TAG Syntax for Tamil have not been entirely successful due to the complexity of its specification and the rich morphology of Tamil language. In this paper we present a minimalistic TAG for Tamil without much morphological considerations and also introduce a parser implementation with some obvious variations from the XTAG system
Improving the Performance of English-Tamil Statistical Machine Translation System using Source-Side Pre-Processing
Sep 29, 2014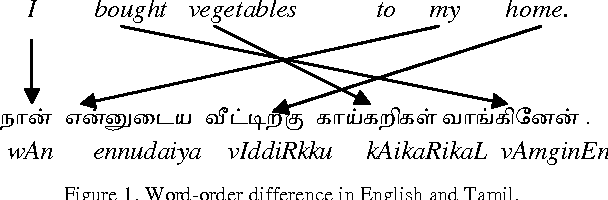
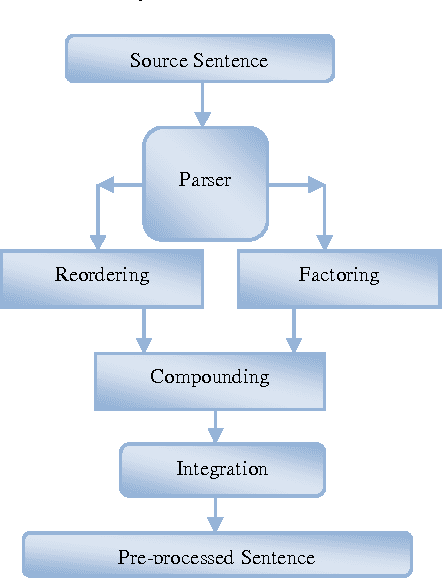
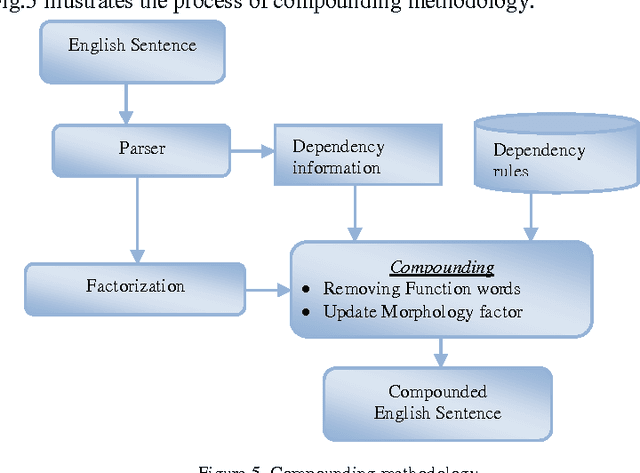

Machine Translation is one of the major oldest and the most active research area in Natural Language Processing. Currently, Statistical Machine Translation (SMT) dominates the Machine Translation research. Statistical Machine Translation is an approach to Machine Translation which uses models to learn translation patterns directly from data, and generalize them to translate a new unseen text. The SMT approach is largely language independent, i.e. the models can be applied to any language pair. Statistical Machine Translation (SMT) attempts to generate translations using statistical methods based on bilingual text corpora. Where such corpora are available, excellent results can be attained translating similar texts, but such corpora are still not available for many language pairs. Statistical Machine Translation systems, in general, have difficulty in handling the morphology on the source or the target side especially for morphologically rich languages. Errors in morphology or syntax in the target language can have severe consequences on meaning of the sentence. They change the grammatical function of words or the understanding of the sentence through the incorrect tense information in verb. Baseline SMT also known as Phrase Based Statistical Machine Translation (PBSMT) system does not use any linguistic information and it only operates on surface word form. Recent researches shown that adding linguistic information helps to improve the accuracy of the translation with less amount of bilingual corpora. Adding linguistic information can be done using the Factored Statistical Machine Translation system through pre-processing steps. This paper investigates about how English side pre-processing is used to improve the accuracy of English-Tamil SMT system.
Hierarchical Approach for Total Variation Digital Image Inpainting
Jul 12, 2013


The art of recovering an image from damage in an undetectable form is known as inpainting. The manual work of inpainting is most often a very time consuming process. Due to digitalization of this technique, it is automatic and faster. In this paper, after the user selects the regions to be reconstructed, the algorithm automatically reconstruct the lost regions with the help of the information surrounding them. The existing methods perform very well when the region to be reconstructed is very small, but fails in proper reconstruction as the area increases. This paper describes a Hierarchical method by which the area to be inpainted is reduced in multiple levels and Total Variation(TV) method is used to inpaint in each level. This algorithm gives better performance when compared with other existing algorithms such as nearest neighbor interpolation, Inpainting through Blurring and Sobolev Inpainting.
G-Lets: Signal Processing Using Transformation Groups
Jan 14, 2012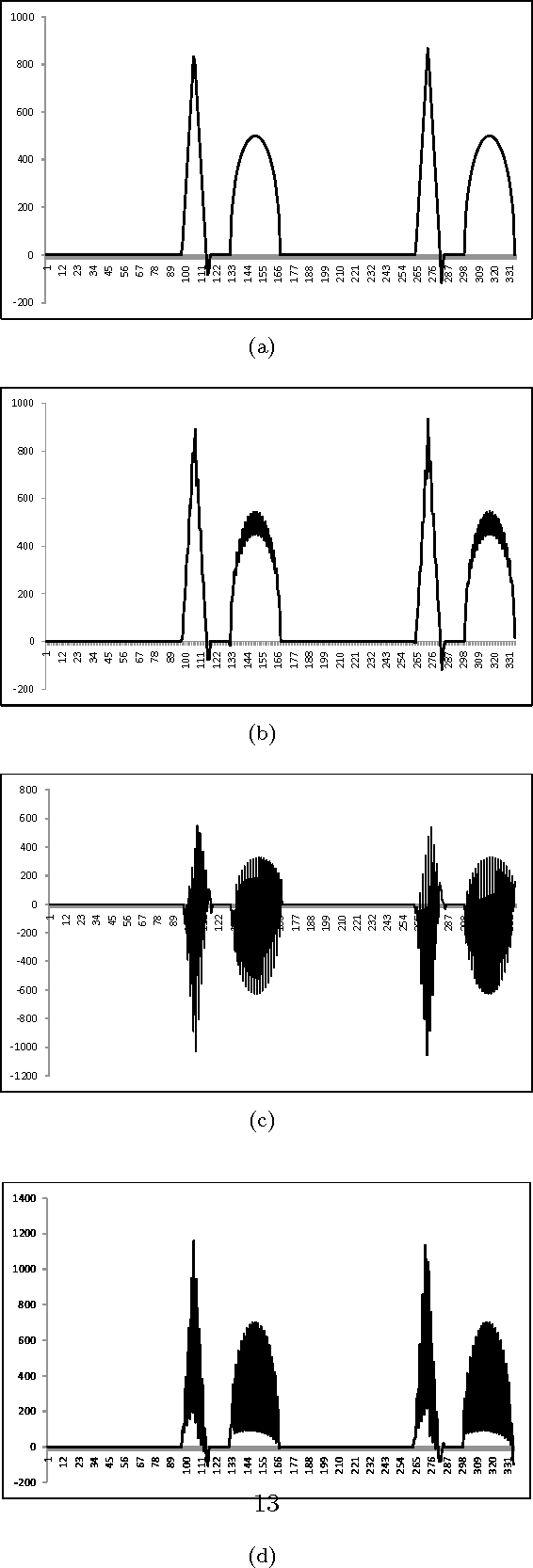
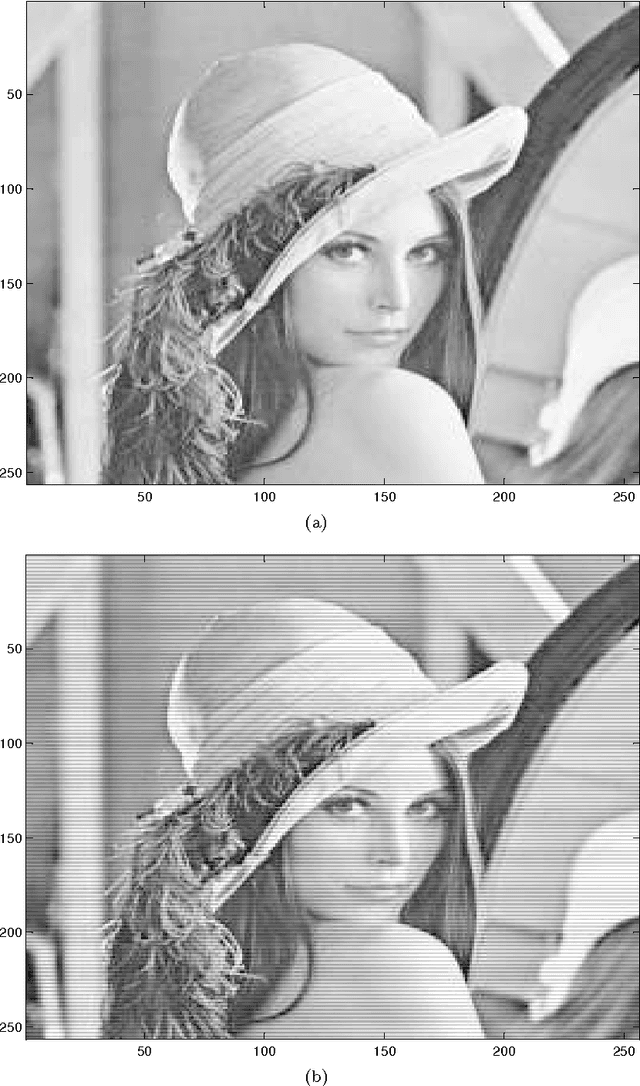


We present an algorithm using transformation groups and their irreducible representations to generate an orthogonal basis for a signal in the vector space of the signal. It is shown that multiresolution analysis can be done with amplitudes using a transformation group. G-lets is thus not a single transform, but a group of linear transformations related by group theory. The algorithm also specifies that a multiresolution and multiscale analysis for each resolution is possible in terms of frequencies. Separation of low and high frequency components of each amplitude resolution is facilitated by G-lets. Using conjugacy classes of the transformation group, more than one set of basis may be generated, giving a different perspective of the signal through each basis. Applications for this algorithm include edge detection, feature extraction, denoising, face recognition, compression, and more. We analyze this algorithm using dihedral groups as an example. We demonstrate the results with an ECG signal and the standard `Lena' image.