 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptical character recognition quality affects perceived usefulness of historical newspaper clippings
Jun 01, 2022

Introduction. We study effect of different quality optical character recognition in interactive information retrieval with a collection of one digitized historical Finnish newspaper. Method. This study is based on the simulated interactive information retrieval work task model. Thirty-two users made searches to an article collection of Finnish newspaper Uusi Suometar 1869-1918 with ca. 1.45 million auto segmented articles. Our article search database had two versions of each article with different quality optical character recognition. Each user performed six pre-formulated and six self-formulated short queries and evaluated subjectively the top-10 results using graded relevance scale of 0-3 without knowing about the optical character recognition quality differences of the otherwise identical articles. Analysis. Analysis of the user evaluations was performed by comparing mean averages of evaluations scores in user sessions. Differences of query results were detected by analysing lengths of returned articles in pre-formulated and self-formulated queries and number of different documents retrieved overall in these two sessions. Results. The main result of the study is that improved optical character recognition quality affects perceived usefulness of historical newspaper articles positively. Conclusions. We were able to show that improvement in optical character recognition quality of documents leads to higher mean relevance evaluation scores of query results in our historical newspaper collection. To the best of our knowledge this simulated interactive user-task is the first one showing empirically that users' subjective relevance assessments are affected by a change in the quality of optically read text.
OCR quality affects perceived usefulness of historical newspaper clippings -- a user study
Mar 04, 2022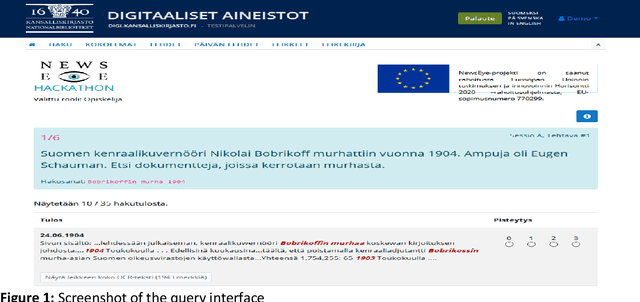
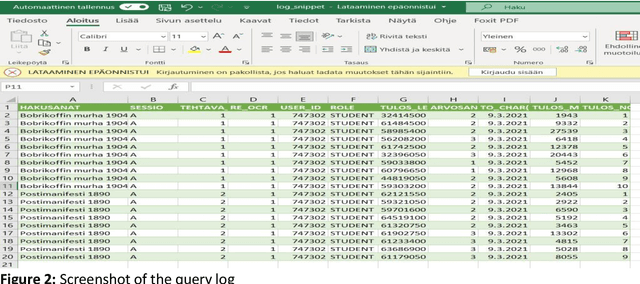
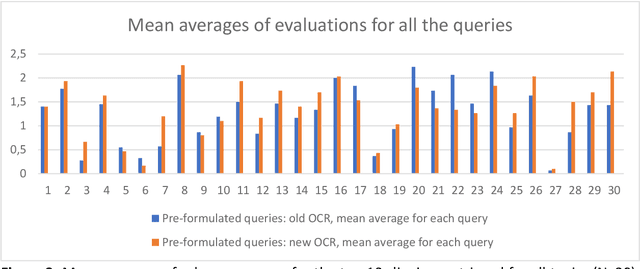
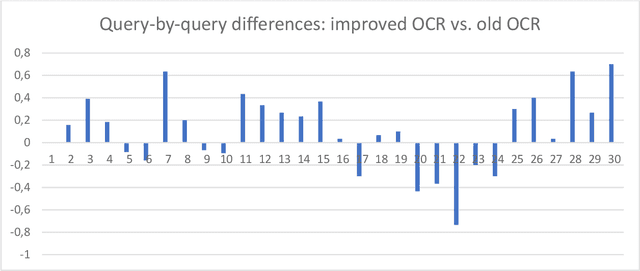
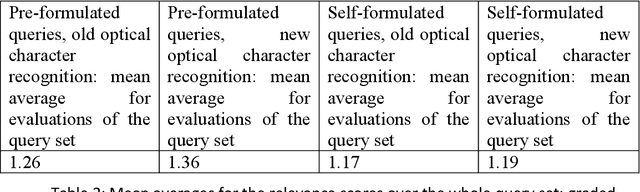
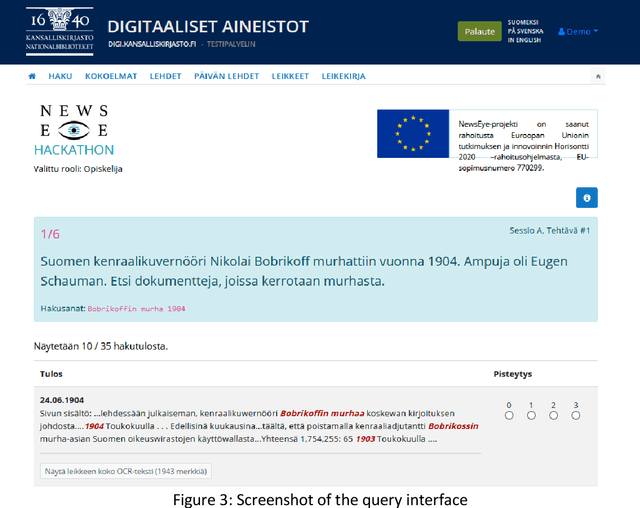
Effects of Optical Character Recognition (OCR) quality on historical information retrieval have so far been studied in data-oriented scenarios regarding the effectiveness of retrieval results. Such studies have either focused on the effects of artificially degraded OCR quality (see, e.g., [1-2]) or utilized test collections containing texts based on authentic low quality OCR data (see, e.g., [3]). In this paper the effects of OCR quality are studied in a user-oriented information retrieval setting. Thirty-two users evaluated subjectively query results of six topics each (out of 30 topics) based on pre-formulated queries using a simulated work task setting. To the best of our knowledge our simulated work task experiment is the first one showing empirically that users' subjective relevance assessments of retrieved documents are affected by a change in the quality of optically read text. Users of historical newspaper collections have so far commented effects of OCR'ed data quality mainly in impressionistic ways, and controlled user environments for studying effects of OCR quality on users' relevance assessments of the retrieval results have so far been missing. To remedy this The National Library of Finland (NLF) set up an experimental query environment for the contents of one Finnish historical newspaper, Uusi Suometar 1869-1918, to be able to compare users' evaluation of search results of two different OCR qualities for digitized newspaper articles. The query interface was able to present the same underlying document for the user based on two alternatives: either based on the lower OCR quality, or based on the higher OCR quality, and the choice was randomized. The users did not know about quality differences in the article texts they evaluated. The main result of the study is that improved optical character recognition quality affects perceived usefulness of historical newspaper articles significantly. The mean average evaluation score for the improved OCR results was 7.94% higher than the mean average evaluation score of the old OCR results.
How to do lexical quality estimation of a large OCRed historical Finnish newspaper collection with scarce resources
Nov 16, 2016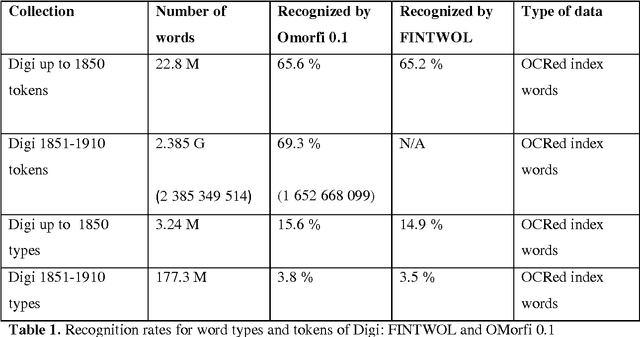
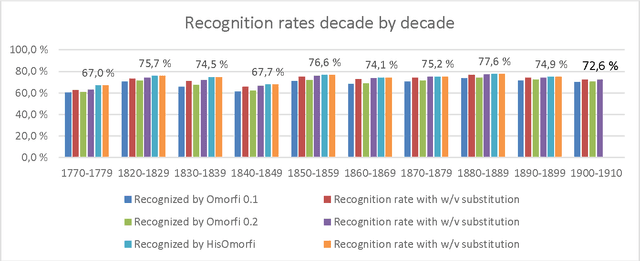

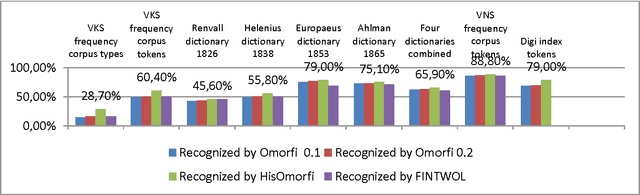
The National Library of Finland has digitized the historical newspapers published in Finland between 1771 and 1910. This collection contains approximately 1.95 million pages in Finnish and Swedish. Finnish part of the collection consists of about 2.40 billion words. The National Library's Digital Collections are offered via the digi.kansalliskirjasto.fi web service, also known as Digi. Part of the newspaper material (from 1771 to 1874) is also available freely downloadable in The Language Bank of Finland provided by the FINCLARIN consortium. The collection can also be accessed through the Korp environment that has been developed by Spr{\aa}kbanken at the University of Gothenburg and extended by FINCLARIN team at the University of Helsinki to provide concordances of text resources. A Cranfield style information retrieval test collection has also been produced out of a small part of the Digi newspaper material at the University of Tampere. Quality of OCRed collections is an important topic in digital humanities, as it affects general usability and searchability of collections. There is no single available method to assess quality of large collections, but different methods can be used to approximate quality. This paper discusses different corpus analysis style methods to approximate overall lexical quality of the Finnish part of the Digi collection. Methods include usage of parallel samples and word error rates, usage of morphological analyzers, frequency analysis of words and comparisons to comparable edited lexical data. Our aim in the quality analysis is twofold: firstly to analyze the present state of the lexical data and secondly, to establish a set of assessment methods that build up a compact procedure for quality assessment after e.g. new OCRing or post correction of the material. In the discussion part of the paper we shall synthesize results of our different analyses.