 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Fidelity Image Synthesis With Deep VAEs In Latent Space
Mar 23, 2023We present fast, realistic image generation on high-resolution, multimodal datasets using hierarchical variational autoencoders (VAEs) trained on a deterministic autoencoder's latent space. In this two-stage setup, the autoencoder compresses the image into its semantic features, which are then modeled with a deep VAE. With this method, the VAE avoids modeling the fine-grained details that constitute the majority of the image's code length, allowing it to focus on learning its structural components. We demonstrate the effectiveness of our two-stage approach, achieving a FID of 9.34 on the ImageNet-256 dataset which is comparable to BigGAN. We make our implementation available online.
Optimizing Hierarchical Image VAEs for Sample Quality
Oct 18, 2022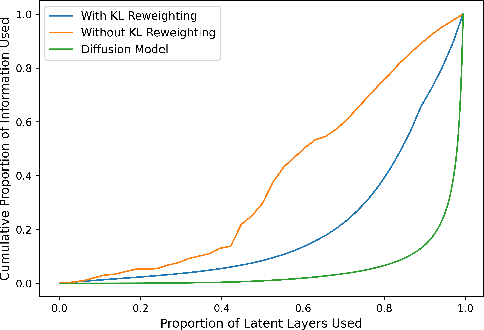
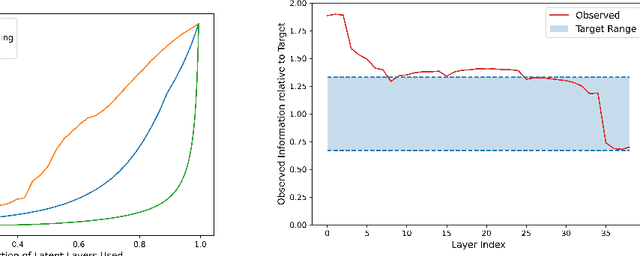
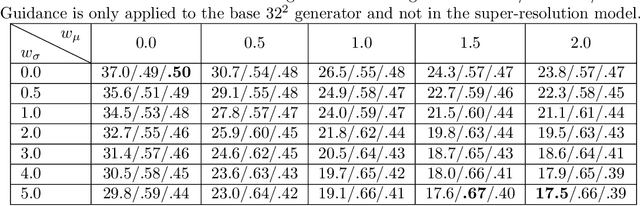
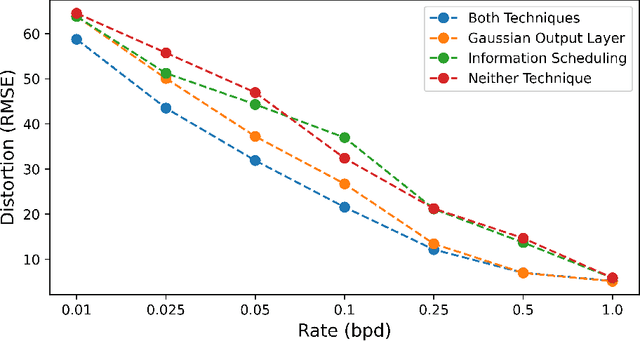
While hierarchical variational autoencoders (VAEs) have achieved great density estimation on image modeling tasks, samples from their prior tend to look less convincing than models with similar log-likelihood. We attribute this to learned representations that over-emphasize compressing imperceptible details of the image. To address this, we introduce a KL-reweighting strategy to control the amount of infor mation in each latent group, and employ a Gaussian output layer to reduce sharpness in the learning objective. To trade off image diversity for fidelity, we additionally introduce a classifier-free guidance strategy for hierarchical VAEs. We demonstrate the effectiveness of these techniques in our experiments. Code is available at https://github.com/tcl9876/visual-vae.
Improving Diffusion Model Efficiency Through Patching
Jul 09, 2022
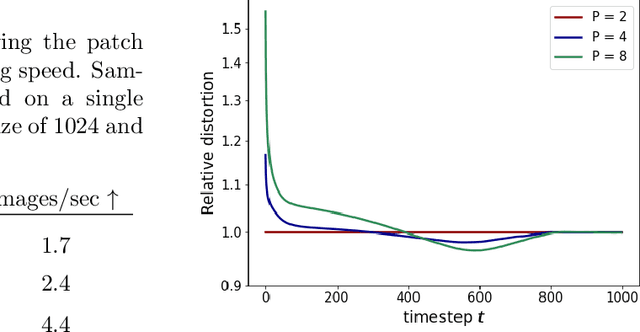
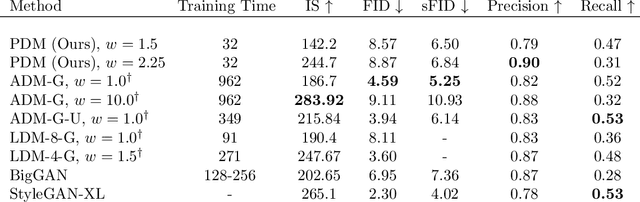
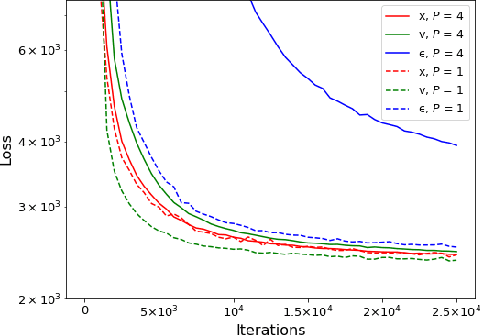
Diffusion models are a powerful class of generative models that iteratively denoise samples to produce data. While many works have focused on the number of iterations in this sampling procedure, few have focused on the cost of each iteration. We find that adding a simple ViT-style patching transformation can considerably reduce a diffusion model's sampling time and memory usage. We justify our approach both through an analysis of the diffusion model objective, and through empirical experiments on LSUN Church, ImageNet 256, and FFHQ 1024. We provide implementations in Tensorflow and Pytorch.
Knowledge Distillation in Iterative Generative Models for Improved Sampling Speed
Jan 07, 2021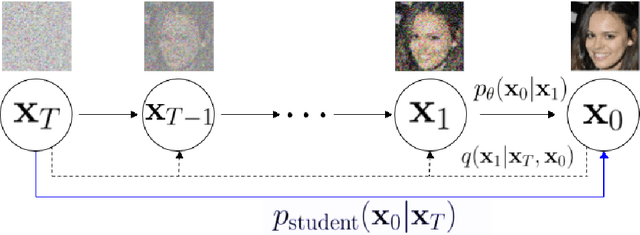



Iterative generative models, such as noise conditional score networks and denoising diffusion probabilistic models, produce high quality samples by gradually denoising an initial noise vector. However, their denoising process has many steps, making them 2-3 orders of magnitude slower than other generative models such as GANs and VAEs. In this paper, we establish a novel connection between knowledge distillation and image generation with a technique that distills a multi-step denoising process into a single step, resulting in a sampling speed similar to other single-step generative models. Our Denoising Student generates high quality samples comparable to GANs on the CIFAR-10 and CelebA datasets, without adversarial training. We demonstrate that our method scales to higher resolutions through experiments on 256 x 256 LSUN. Code and checkpoints are available at https://github.com/tcl9876/Denoising_Student
Diffusion models for Handwriting Generation
Nov 13, 2020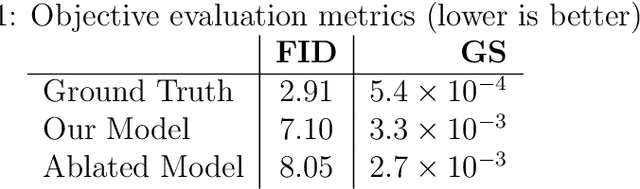
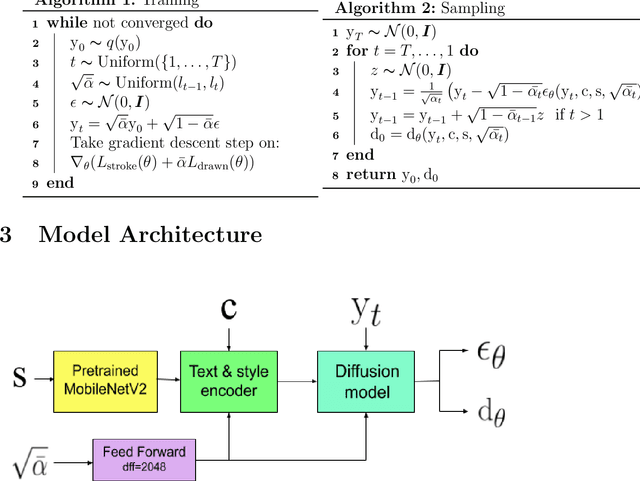

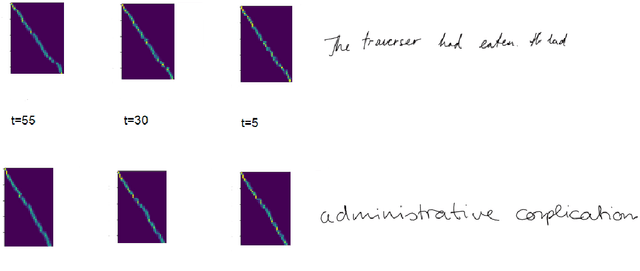
In this paper, we propose a diffusion probabilistic model for handwriting generation. Diffusion models are a class of generative models where samples start from Gaussian noise and are gradually denoised to produce output. Our method of handwriting generation does not require using any text-recognition based, writer-style based, or adversarial loss functions, nor does it require training of auxiliary networks. Our model is able to incorporate writer stylistic features directly from image data, eliminating the need for user interaction during sampling. Experiments reveal that our model is able to generate realistic , high quality images of handwritten text in a similar style to a given writer. Our implementation can be found at https://github.com/tcl9876/Diffusion-Handwriting-Generation