 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Hierarchical Image VAEs for Sample Quality
Paper and Code
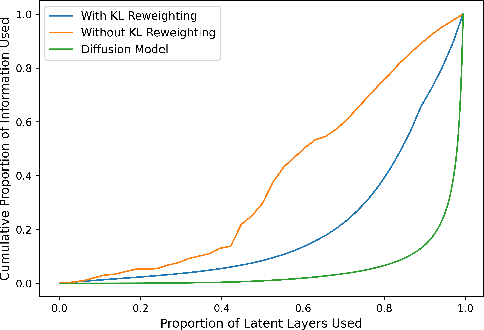
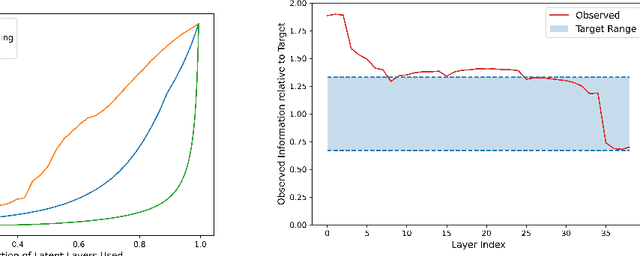
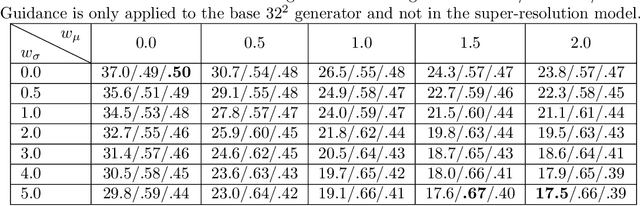
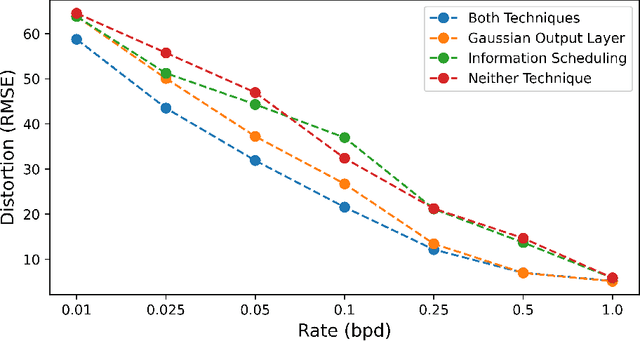
While hierarchical variational autoencoders (VAEs) have achieved great density estimation on image modeling tasks, samples from their prior tend to look less convincing than models with similar log-likelihood. We attribute this to learned representations that over-emphasize compressing imperceptible details of the image. To address this, we introduce a KL-reweighting strategy to control the amount of infor mation in each latent group, and employ a Gaussian output layer to reduce sharpness in the learning objective. To trade off image diversity for fidelity, we additionally introduce a classifier-free guidance strategy for hierarchical VAEs. We demonstrate the effectiveness of these techniques in our experiments. Code is available at https://github.com/tcl9876/visual-vae.