 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError rate control for classification rules in multiclass mixture models
Sep 29, 2021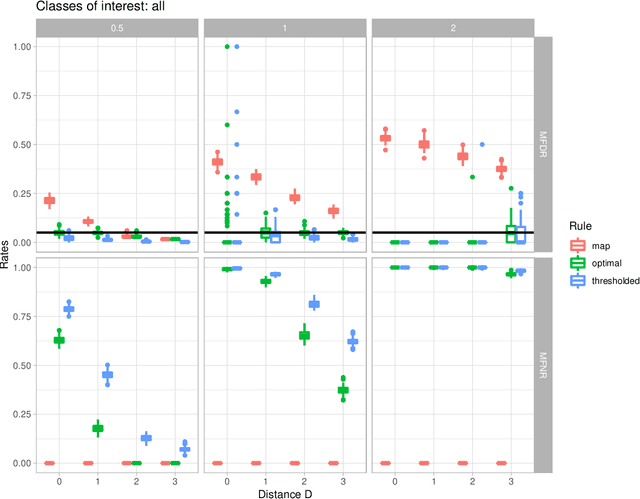
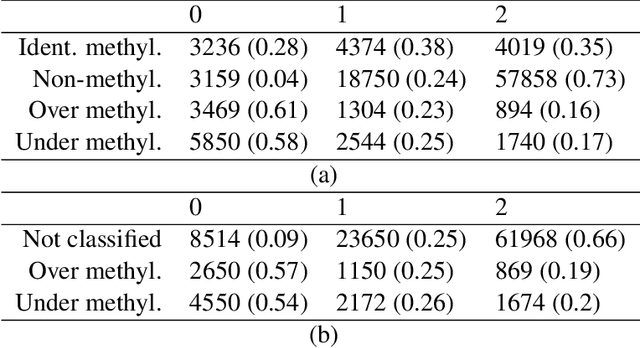
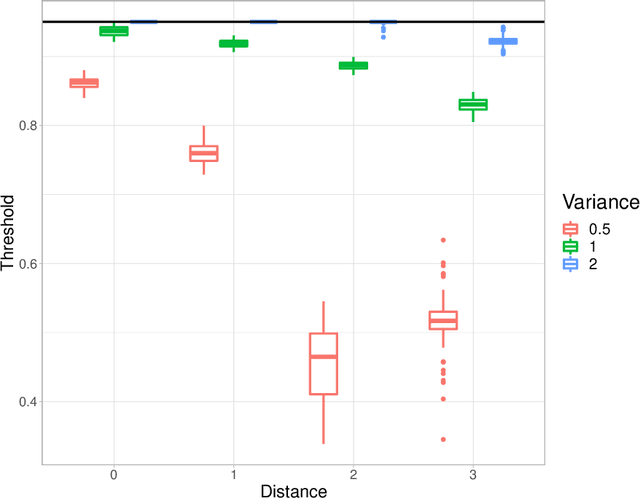
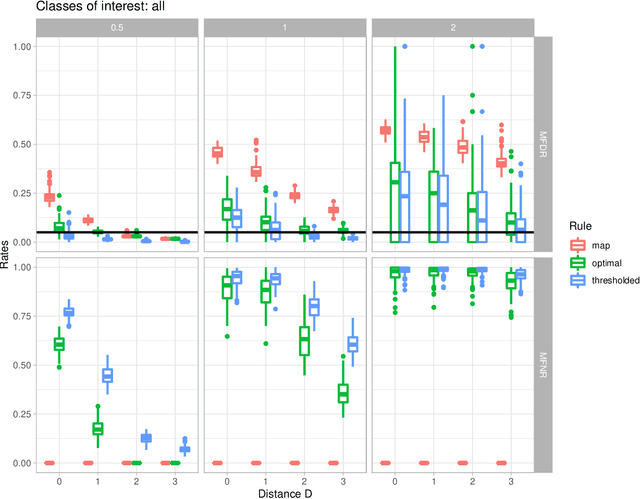
In the context of finite mixture models one considers the problem of classifying as many observations as possible in the classes of interest while controlling the classification error rate in these same classes. Similar to what is done in the framework of statistical test theory, different type I and type II-like classification error rates can be defined, along with their associated optimal rules, where optimality is defined as minimizing type II error rate while controlling type I error rate at some nominal level. It is first shown that finding an optimal classification rule boils down to searching an optimal region in the observation space where to apply the classical Maximum A Posteriori (MAP) rule. Depending on the misclassification rate to be controlled, the shape of the optimal region is provided, along with a heuristic to compute the optimal classification rule in practice. In particular, a multiclass FDR-like optimal rule is defined and compared to the thresholded MAP rules that is used in most applications. It is shown on both simulated and real datasets that the FDR-like optimal rule may be significantly less conservative than the thresholded MAP rule.