 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Language Understanding Evaluation (CLUE)
Sep 28, 2022



Clinical language processing has received a lot of attention in recent years, resulting in new models or methods for disease phenotyping, mortality prediction, and other tasks. Unfortunately, many of these approaches are tested under different experimental settings (e.g., data sources, training and testing splits, metrics, evaluation criteria, etc.) making it difficult to compare approaches and determine state-of-the-art. To address these issues and facilitate reproducibility and comparison, we present the Clinical Language Understanding Evaluation (CLUE) benchmark with a set of four clinical language understanding tasks, standard training, development, validation and testing sets derived from MIMIC data, as well as a software toolkit. It is our hope that these data will enable direct comparison between approaches, improve reproducibility, and reduce the barrier-to-entry for developing novel models or methods for these clinical language understanding tasks.
Bridging the Knowledge Gap: Enhancing Question Answering with World and Domain Knowledge
Oct 16, 2019
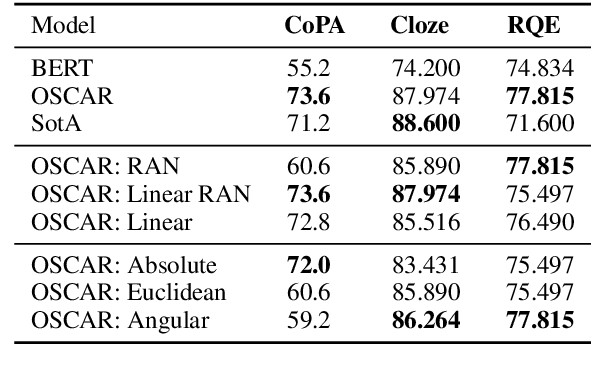
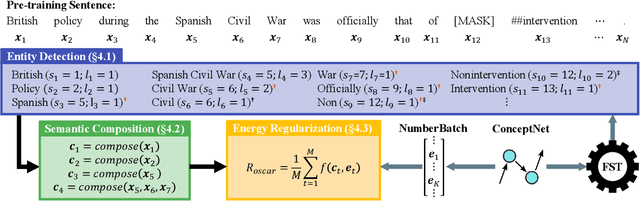
In this paper we present OSCAR (Ontology-based Semantic Composition Augmented Regularization), a method for injecting task-agnostic knowledge from an Ontology or knowledge graph into a neural network during pretraining. We evaluated the impact of including OSCAR when pretraining BERT with Wikipedia articles by measuring the performance when fine-tuning on two question answering tasks involving world knowledge and causal reasoning and one requiring domain (healthcare) knowledge and obtained 33:3%, 18:6%, and 4% improved accuracy compared to pretraining BERT without OSCAR and obtaining new state-of-the-art results on two of the tasks.