 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumerical Generalized Randomized Hamiltonian Monte Carlo for piecewise smooth target densities
Apr 25, 2025Traditional gradient-based sampling methods, like standard Hamiltonian Monte Carlo, require that the desired target distribution is continuous and differentiable. This limits the types of models one can define, although the presented models capture the reality in the observations better. In this project, Generalized Randomized Hamiltonian Monte Carlo (GRHMC) processes for sampling continuous densities with discontinuous gradient and piecewise smooth targets are proposed. The methods combine the advantages of Hamiltonian Monte Carlo methods with the nature of continuous time processes in the form of piecewise deterministic Markov processes to sample from such distributions. It is argued that the techniques lead to GRHMC processes that admit the desired target distribution as the invariant distribution in both scenarios. Simulation experiments verifying this fact and several relevant real-life models are presented, including a new parameterization of the spike and slab prior for regularized linear regression that returns sparse coefficient estimates and a regime switching volatility model.
Tuning diagonal scale matrices for HMC
Mar 12, 2024Three approaches for adaptively tuning diagonal scale matrices for HMC are discussed and compared. The common practice of scaling according to estimated marginal standard deviations is taken as a benchmark. Scaling according to the mean log-target gradient (ISG), and a scaling method targeting that the frequency of when the underlying Hamiltonian dynamics crosses the respective medians should be uniform across dimensions, are taken as alternatives. Numerical studies suggest that the ISG method leads in many cases to more efficient sampling than the benchmark, in particular in cases with strong correlations or non-linear dependencies. The ISG method is also easy to implement, computationally cheap and would be relatively simple to include in automatically tuned codes as an alternative to the benchmark practice.
Randomized Runge-Kutta-Nyström
Oct 11, 2023We present 5/2- and 7/2-order $L^2$-accurate randomized Runge-Kutta-Nystr\"om methods to approximate the Hamiltonian flow underlying various non-reversible Markov chain Monte Carlo chains including unadjusted Hamiltonian Monte Carlo and unadjusted kinetic Langevin chains. Quantitative 5/2-order $L^2$-accuracy upper bounds are provided under gradient and Hessian Lipschitz assumptions on the potential energy function. The superior complexity of the corresponding Markov chains is numerically demonstrated for a selection of `well-behaved', high-dimensional target distributions.
Log-density gradient covariance and automatic metric tensors for Riemann manifold Monte Carlo methods
Nov 03, 2022A metric tensor for Riemann manifold Monte Carlo particularly suited for non-linear Bayesian hierarchical models is proposed. The metric tensor is built from here proposed symmetric positive semidefinite log-density gradient covariance (LGC) matrices. The LGCs measure the joint information content and dependence structure of both a random variable and the parameters of said variable. The proposed methodology is highly automatic and allows for exploitation of any sparsity associated with the model in question. When implemented in conjunction with a Riemann manifold variant of the recently proposed numerical generalized randomized Hamiltonian Monte Carlo processes, the proposed methodology is highly competitive, in particular for the more challenging target distributions associated with Bayesian hierarchical models.
agtboost: Adaptive and Automatic Gradient Tree Boosting Computations
Aug 28, 2020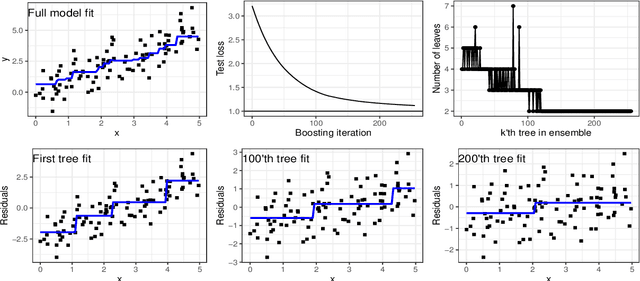

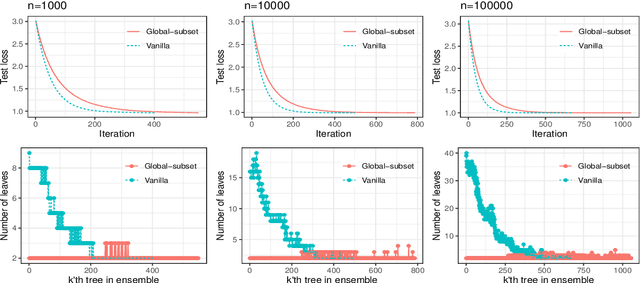
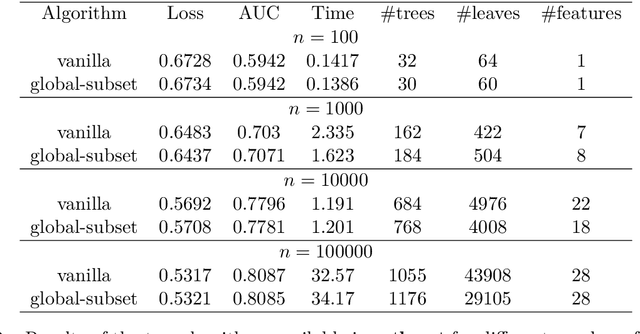
agtboost is an R package implementing fast gradient tree boosting computations in a manner similar to other established frameworks such as xgboost and LightGBM, but with significant decreases in computation time and required mathematical and technical knowledge. The package automatically takes care of split/no-split decisions and selects the number of trees in the gradient tree boosting ensemble, i.e., agtboost adapts the complexity of the ensemble automatically to the information in the data. All of this is done during a single training run, which is made possible by utilizing developments in information theory for tree algorithms {\tt arXiv:2008.05926v1 [stat.ME]}. agtboost also comes with a feature importance function that eliminates the common practice of inserting noise features. Further, a useful model validation function performs the Kolmogorov-Smirnov test on the learned distribution.
An information criterion for automatic gradient tree boosting
Aug 13, 2020
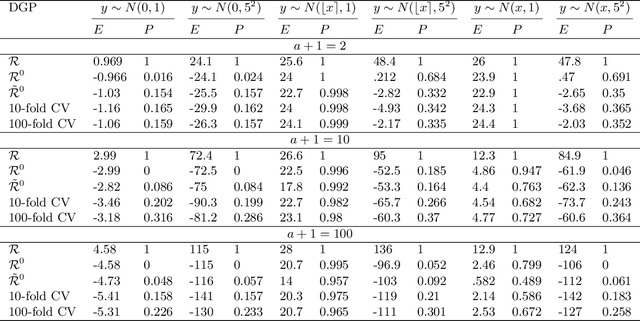
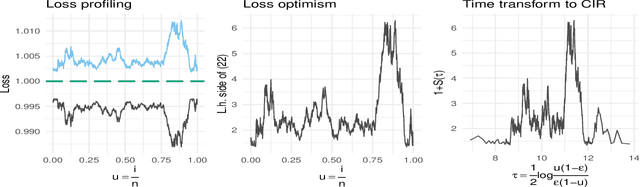
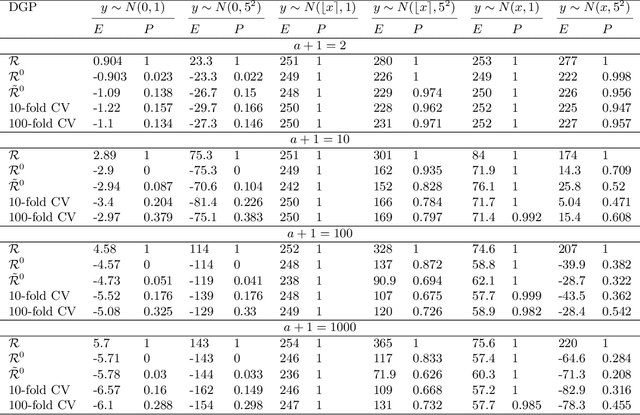
An information theoretic approach to learning the complexity of classification and regression trees and the number of trees in gradient tree boosting is proposed. The optimism (test loss minus training loss) of the greedy leaf splitting procedure is shown to be the maximum of a Cox-Ingersoll-Ross process, from which a generalization-error based information criterion is formed. The proposed procedure allows fast local model selection without cross validation based hyper parameter tuning, and hence efficient and automatic comparison among the large number of models performed during each boosting iteration. Relative to xgboost, speedups on numerical experiments ranges from around 10 to about 1400, at similar predictive-power measured in terms of test-loss.
Connecting the Dots: Towards Continuous Time Hamiltonian Monte Carlo
May 04, 2020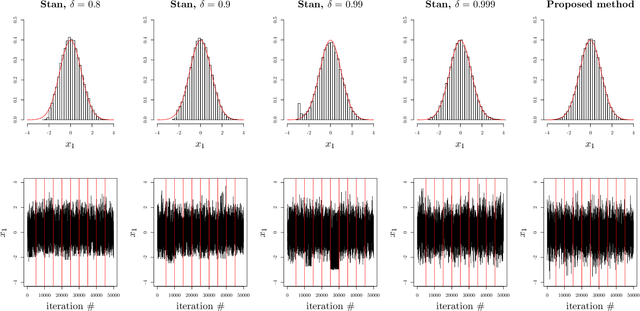


Continuous time Hamiltonian Monte Carlo is introduced, as a powerful alternative to Markov chain Monte Carlo methods for continuous target distributions. The method is constructed in two steps: First Hamiltonian dynamics are chosen as the deterministic dynamics in a continuous time piecewise deterministic Markov process. Under very mild restrictions, such a process will have the desired target distribution as an invariant distribution. Secondly, the numerical implementation of such processes, based on adaptive numerical integration of second order ordinary differential equations is considered. The numerical implementation yields an approximate, yet highly robust algorithm that, unlike conventional Hamiltonian Monte Carlo, enables the exploitation of the complete Hamiltonian trajectories (and hence the title). The proposed algorithm may yield large speedups and improvements in stability relative to relevant benchmarks, while incurring numerical errors that are negligible relative to the overall Monte Carlo errors.