 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientific Machine Learning Benchmarks
Oct 25, 2021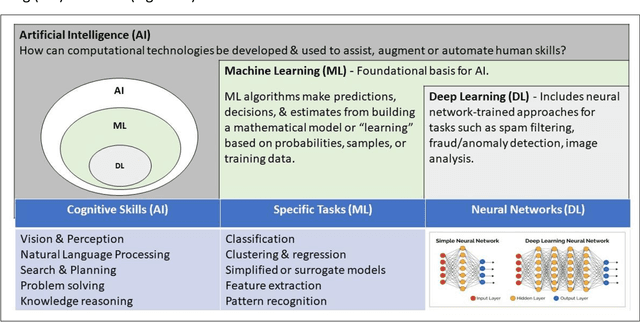
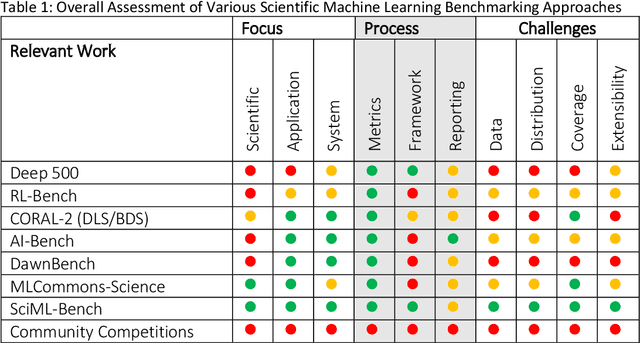
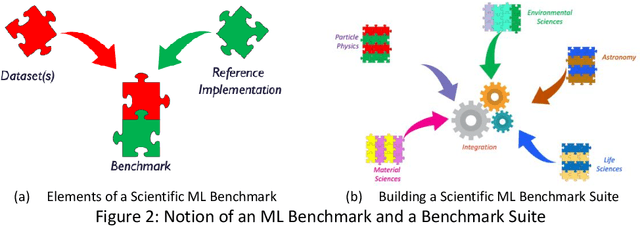
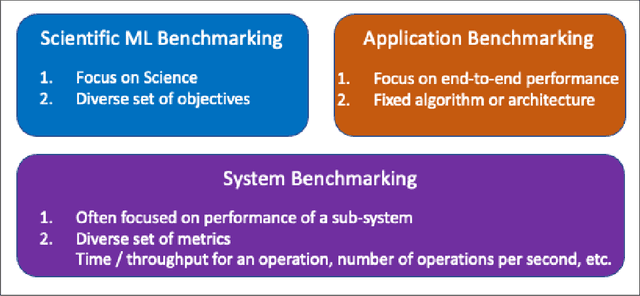
The breakthrough in Deep Learning neural networks has transformed the use of AI and machine learning technologies for the analysis of very large experimental datasets. These datasets are typically generated by large-scale experimental facilities at national laboratories. In the context of science, scientific machine learning focuses on training machines to identify patterns, trends, and anomalies to extract meaningful scientific insights from such datasets. With a new generation of experimental facilities, the rate of data generation and the scale of data volumes will increasingly require the use of more automated data analysis. At present, identifying the most appropriate machine learning algorithm for the analysis of any given scientific dataset is still a challenge for scientists. This is due to many different machine learning frameworks, computer architectures, and machine learning models. Historically, for modelling and simulation on HPC systems such problems have been addressed through benchmarking computer applications, algorithms, and architectures. Extending such a benchmarking approach and identifying metrics for the application of machine learning methods to scientific datasets is a new challenge for both scientists and computer scientists. In this paper, we describe our approach to the development of scientific machine learning benchmarks and review other approaches to benchmarking scientific machine learning.
Machine Learning and Big Scientific Data
Oct 12, 2019
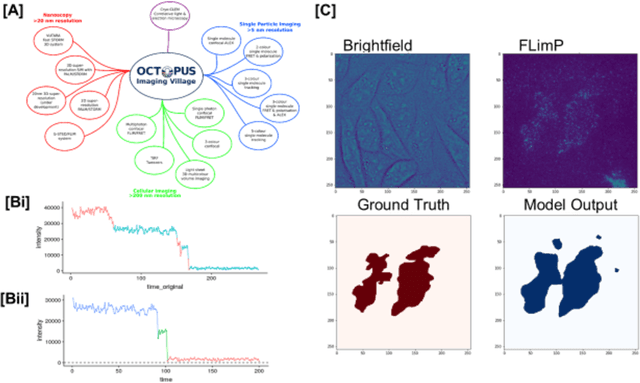
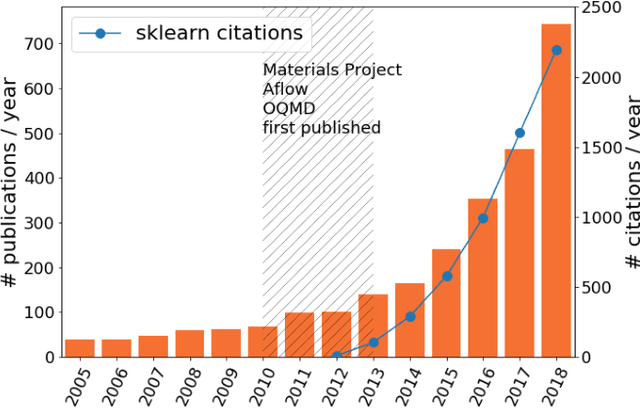
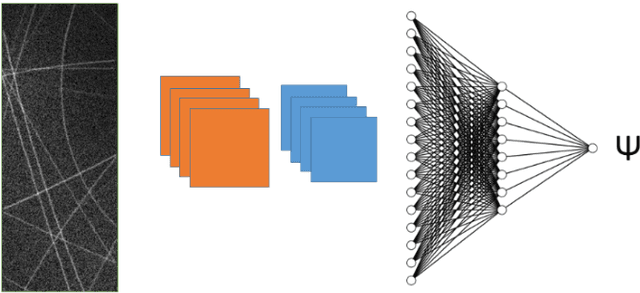
This paper reviews some of the challenges posed by the huge growth of experimental data generated by the new generation of large-scale experiments at UK national facilities at the Rutherford Appleton Laboratory site at Harwell near Oxford. Such "Big Scientific Data" comes from the Diamond Light Source and Electron Microscopy Facilities, the ISIS Neutron and Muon Facility, and the UK's Central Laser Facility. Increasingly, scientists are now needing to use advanced machine learning and other AI technologies both to automate parts of the data pipeline and also to help find new scientific discoveries in the analysis of their data. For commercially important applications, such as object recognition, natural language processing and automatic translation, deep learning has made dramatic breakthroughs. Google's DeepMind has now also used deep learning technology to develop their AlphaFold tool to make predictions for protein folding. Remarkably, they have been able to achieve some spectacular results for this specific scientific problem. Can deep learning be similarly transformative for other scientific problems? After a brief review of some initial applications of machine learning at the Rutherford Appleton Laboratory, we focus on challenges and opportunities for AI in advancing materials science. Finally, we discuss the importance of developing some realistic machine learning benchmarks using Big Scientific Data coming from a number of different scientific domains. We conclude with some initial examples of our "SciML" benchmark suite and of the research challenges these benchmarks will enable.