 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Extraction and Adversarial Attacks on Neural Networks using Switching Power Information
Jun 15, 2021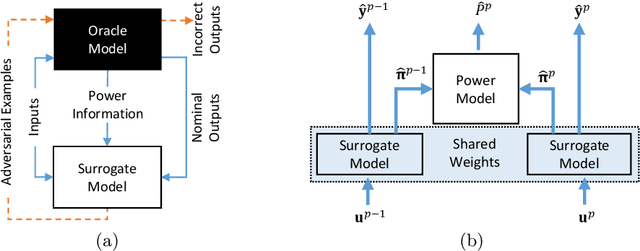
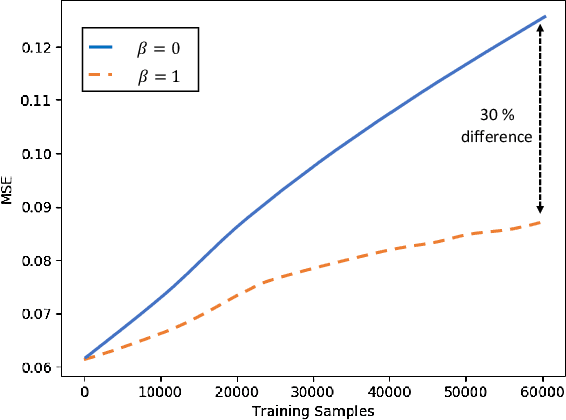
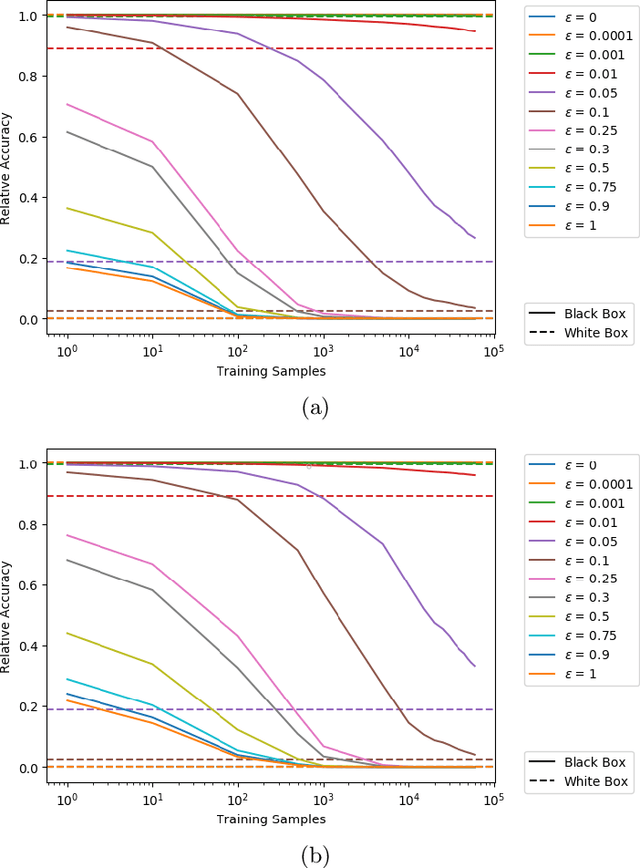
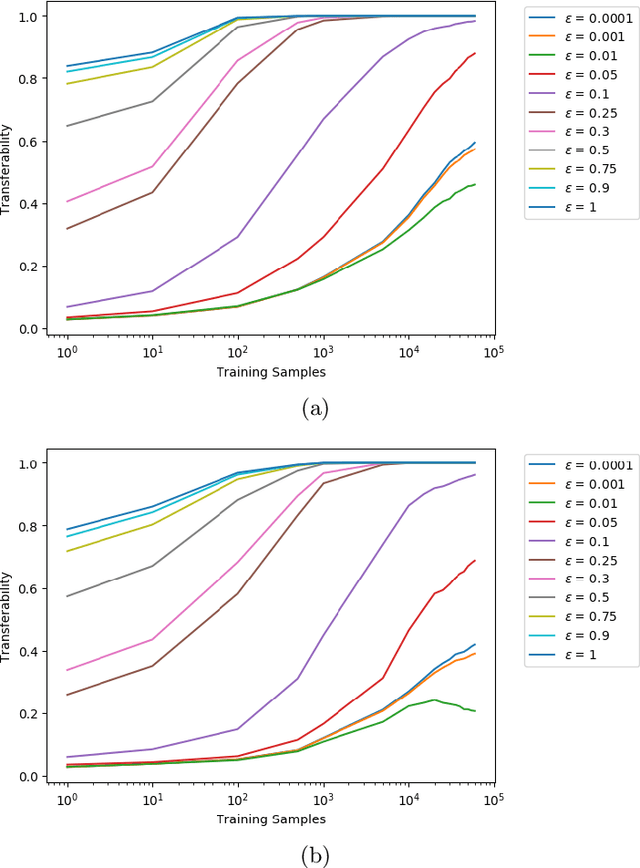
Artificial neural networks (ANNs) have gained significant popularity in the last decade for solving narrow AI problems in domains such as healthcare, transportation, and defense. As ANNs become more ubiquitous, it is imperative to understand their associated safety, security, and privacy vulnerabilities. Recently, it has been shown that ANNs are susceptible to a number of adversarial evasion attacks--inputs that cause the ANN to make high-confidence misclassifications despite being almost indistinguishable from the data used to train and test the network. This work explores to what degree finding these examples maybe aided by using side-channel information, specifically switching power consumption, of hardware implementations of ANNs. A black-box threat scenario is assumed, where an attacker has access to the ANN hardware's input, outputs, and topology, but the trained model parameters are unknown. Then, a surrogate model is trained to have similar functional (i.e. input-output mapping) and switching power characteristics as the oracle (black-box) model. Our results indicate that the inclusion of power consumption data increases the fidelity of the model extraction by up to 30 percent based on a mean square error comparison of the oracle and surrogate weights. However, transferability of adversarial examples from the surrogate to the oracle model was not significantly affected.