 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Accuracy and Latency in Multipath Neural Networks
Apr 25, 2021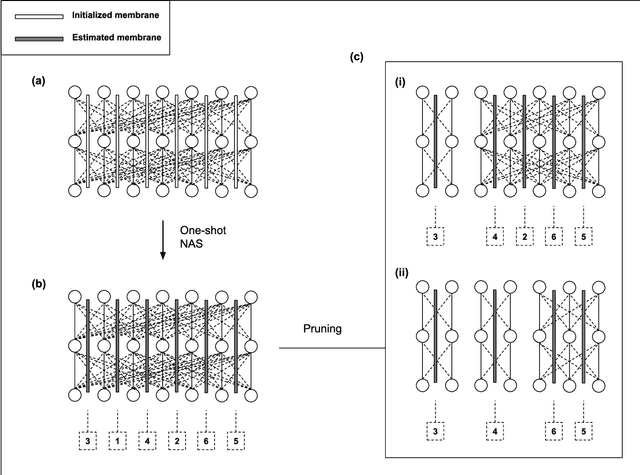
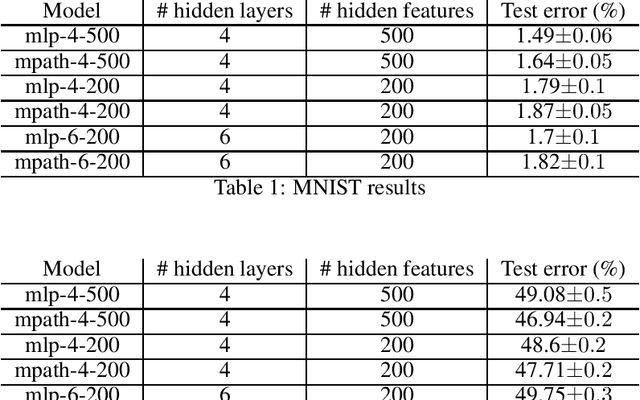
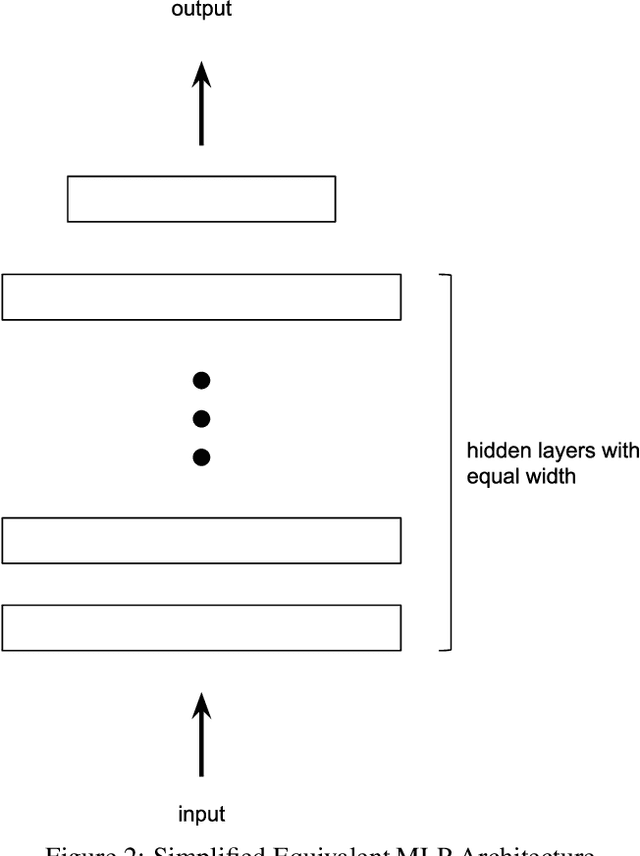
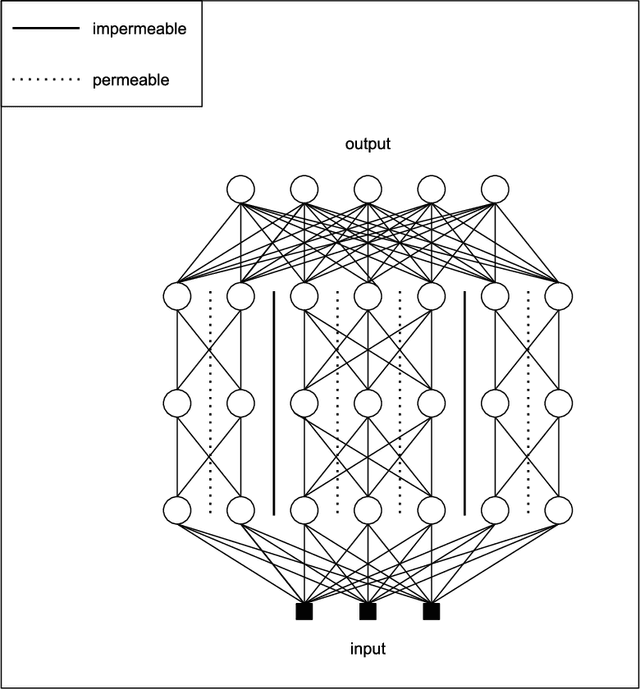
The growing capacity of neural networks has strongly contributed to their success at complex machine learning tasks and the computational demand of such large models has, in turn, stimulated a significant improvement in the hardware necessary to accelerate their computations. However, models with high latency aren't suitable for limited-resource environments such as hand-held and IoT devices. Hence, many deep learning techniques aim to address this problem by developing models with reasonable accuracy without violating the limited-resource constraint. In this work, we use a one-shot neural architecture search model to implicitly evaluate the performance of an intractable number of multipath neural networks. Combining this architecture search with a pruning technique and architecture sample evaluation, we can model the relation between the accuracy and the latency of a spectrum of models with graded complexity. We show that our method can accurately model the relative performance between models with different latencies and predict the performance of unseen models with good precision across different datasets.
Reducing Catastrophic Forgetting in Modular Neural Networks by Dynamic Information Balancing
Dec 10, 2019



Lifelong learning is a very important step toward realizing robust autonomous artificial agents. Neural networks are the main engine of deep learning, which is the current state-of-the-art technique in formulating adaptive artificial intelligent systems. However, neural networks suffer from catastrophic forgetting when stressed with the challenge of continual learning. We investigate how to exploit modular topology in neural networks in order to dynamically balance the information load between different modules by routing inputs based on the information content in each module so that information interference is minimized. Our dynamic information balancing (DIB) technique adapts a reinforcement learning technique to guide the routing of different inputs based on a reward signal derived from a measure of the information load in each module. Our empirical results show that DIB combined with elastic weight consolidation (EWC) regularization outperforms models with similar capacity and EWC regularization across different task formulations and datasets.
Weight Map Layer for Noise and Adversarial Attack Robustness
May 02, 2019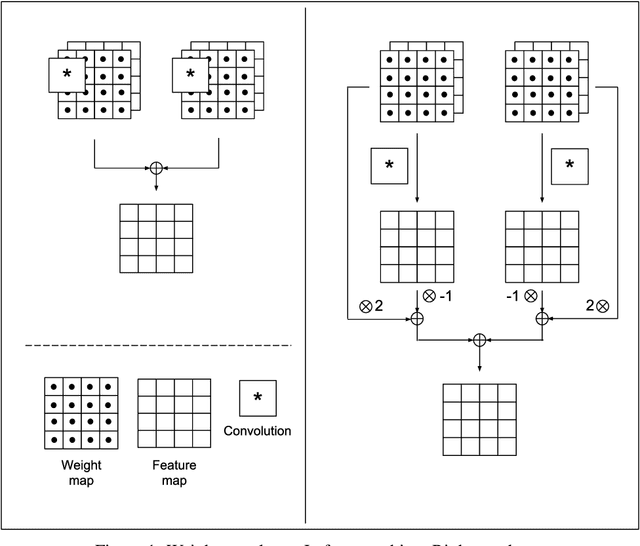



Convolutional neural networks (CNNs) are known for their good performance and generalization in vision-related tasks and have become state-of-the-art in both application and research-based domains. However, just like other neural network models, they suffer from a susceptibility to noise and adversarial attacks. An adversarial defence aims at reducing a neural network's susceptibility to adversarial attacks through learning or architectural modifications. We propose a weight map layer (WM) as a generic architectural addition to CNNs and show that it can increase their robustness to noise and adversarial attacks. We further explain the enhanced robustness of the two WM variants introduced via an adaptive noise-variance amplification (ANVA) hypothesis and provide evidence and insights in support of it. We show that the WM layer can be integrated into scaled up models to increase their noise and adversarial attack robustness, while achieving the same or similar accuracy levels.
A Review of Modularization Techniques in Artificial Neural Networks
Apr 29, 2019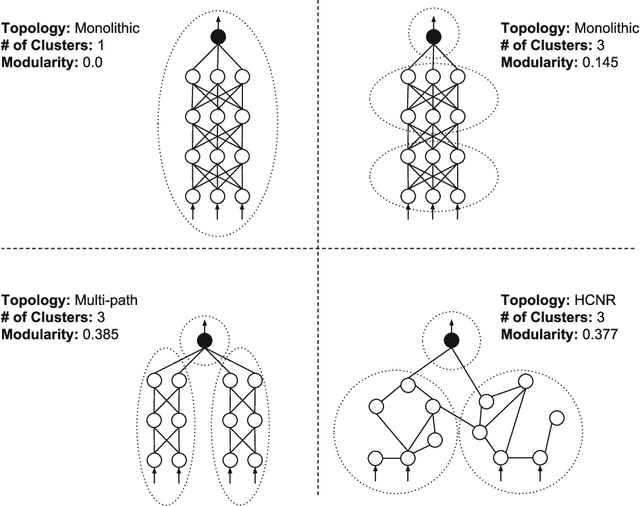


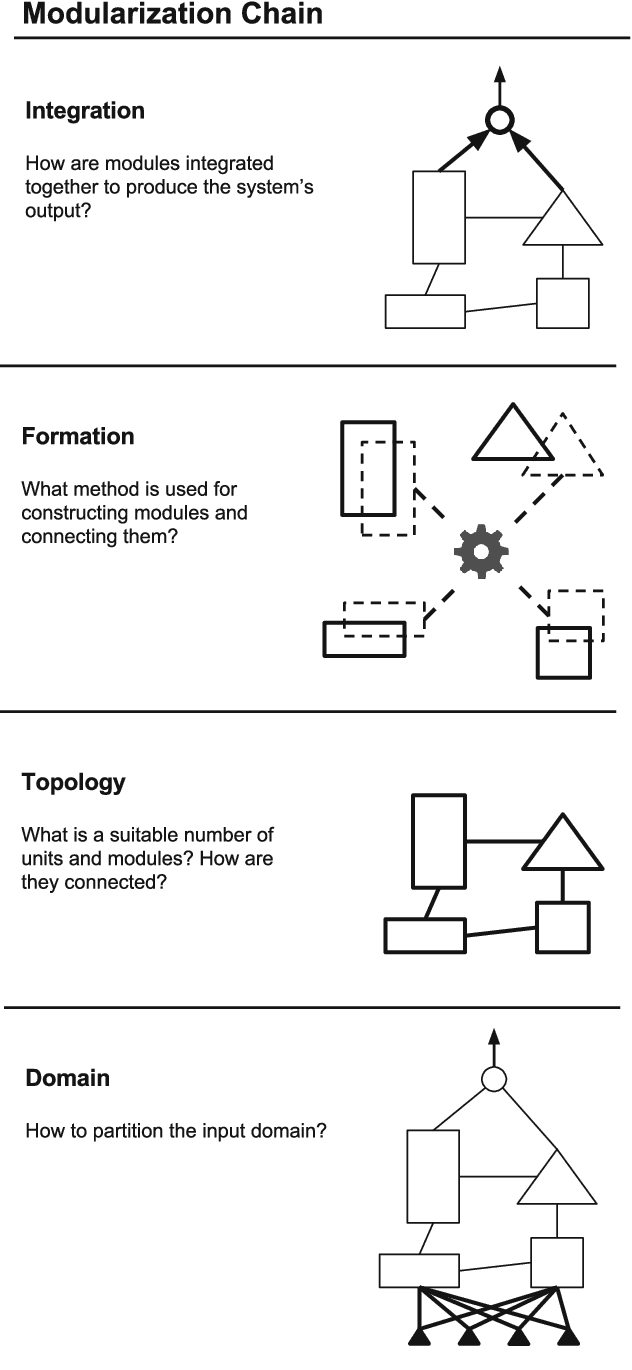
Artificial neural networks (ANNs) have achieved significant success in tackling classical and modern machine learning problems. As learning problems grow in scale and complexity, and expand into multi-disciplinary territory, a more modular approach for scaling ANNs will be needed. Modular neural networks (MNNs) are neural networks that embody the concepts and principles of modularity. MNNs adopt a large number of different techniques for achieving modularization. Previous surveys of modularization techniques are relatively scarce in their systematic analysis of MNNs, focusing mostly on empirical comparisons and lacking an extensive taxonomical framework. In this review, we aim to establish a solid taxonomy that captures the essential properties and relationships of the different variants of MNNs. Based on an investigation of the different levels at which modularization techniques act, we attempt to provide a universal and systematic framework for theorists studying MNNs, also trying along the way to emphasise the strengths and weaknesses of different modularization approaches in order to highlight good practices for neural network practitioners.
Path Capsule Networks
Feb 11, 2019



Capsule network (CapsNet) was introduced as an enhancement over convolutional neural networks, supplementing the latter's invariance properties with equivariance through pose estimation. CapsNet achieved a very decent performance with a shallow architecture and a significant reduction in parameters count. However, the width of the first layer in CapsNet is still contributing to a significant number of its parameters and the shallowness may be limiting the representational power of the capsules. To address these limitations, we introduce Path Capsule Network (PathCapsNet), a deep parallel multi-path version of CapsNet. We show that a judicious coordination of depth, max-pooling, regularization by DropCircuit and a new fan-in routing by agreement technique can achieve better or comparable results to CapsNet, while further reducing the parameter count significantly.